@freixas Agreed I realised that but also that your questions then postulated conclusions that appeared to be not exactly correct or complete (or you were paraphrasing what @OXiDant had said).
@OXiDant Sorry you are wanting to live in “utopia” and it doesn’t exist!
The product you are using is made by Adobe and they “dictate” what the reality is with respect to image handling except they actually don’t when it comes to keywording!!
You are never going to achieve your desired goal and that is not DxPL’s fault any more than it is Capture One’s fault or Photo Mechanics fault it is an (unfortunate) fact of life!
So you will need to learn to live with reality.
During many interactions with DxO, when they existed at all (i.e. the interactions I think DxO still exist), I, amongst others, “campaigned” for an automatic read only process and a process that preserved the incoming keyword data intact so that at least the exports were spared “damage” but it never happened.
You are never transferring a database you are taking data out of one database and passing it to be put into another but I think you know that. As for the “tricky” part it simply comes down to the decision as to how to use the data elements on offer to format the keyword.
You want DxPL to adopt Bridge’s format, what about Photo Mechanic users etc. etc.
I created my “lovely” spreadsheet to discover what the differences are and proposed that DxO could actually allow users to choose the format.
With DxPL’s way of holding hierarchical keywords in the database it would have been simplicity itself to implement , which got zero response from the users and none from DxO! At least that made me start programming again!!
I apologise but please re-state what you believe is happening incorrectly in the transfer from Bridge to DxPL.
Plus please remember only keywords that show as this will be eligible for searching.
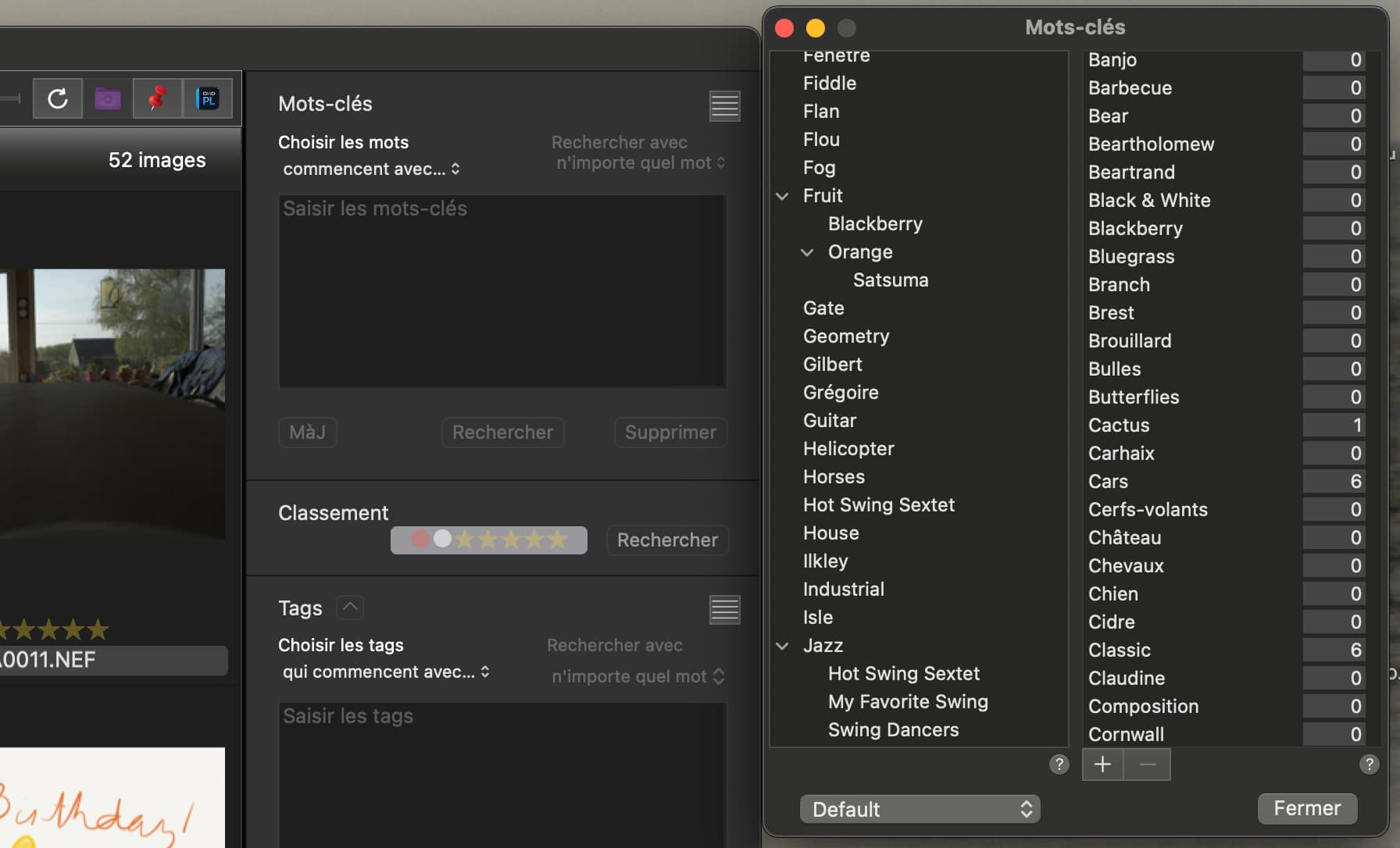
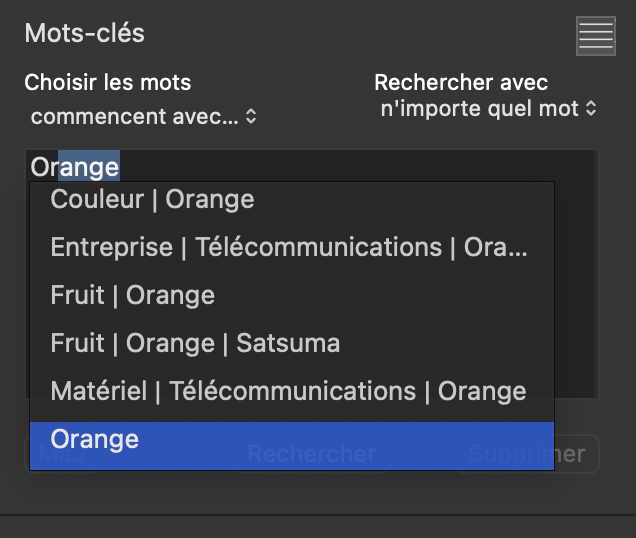
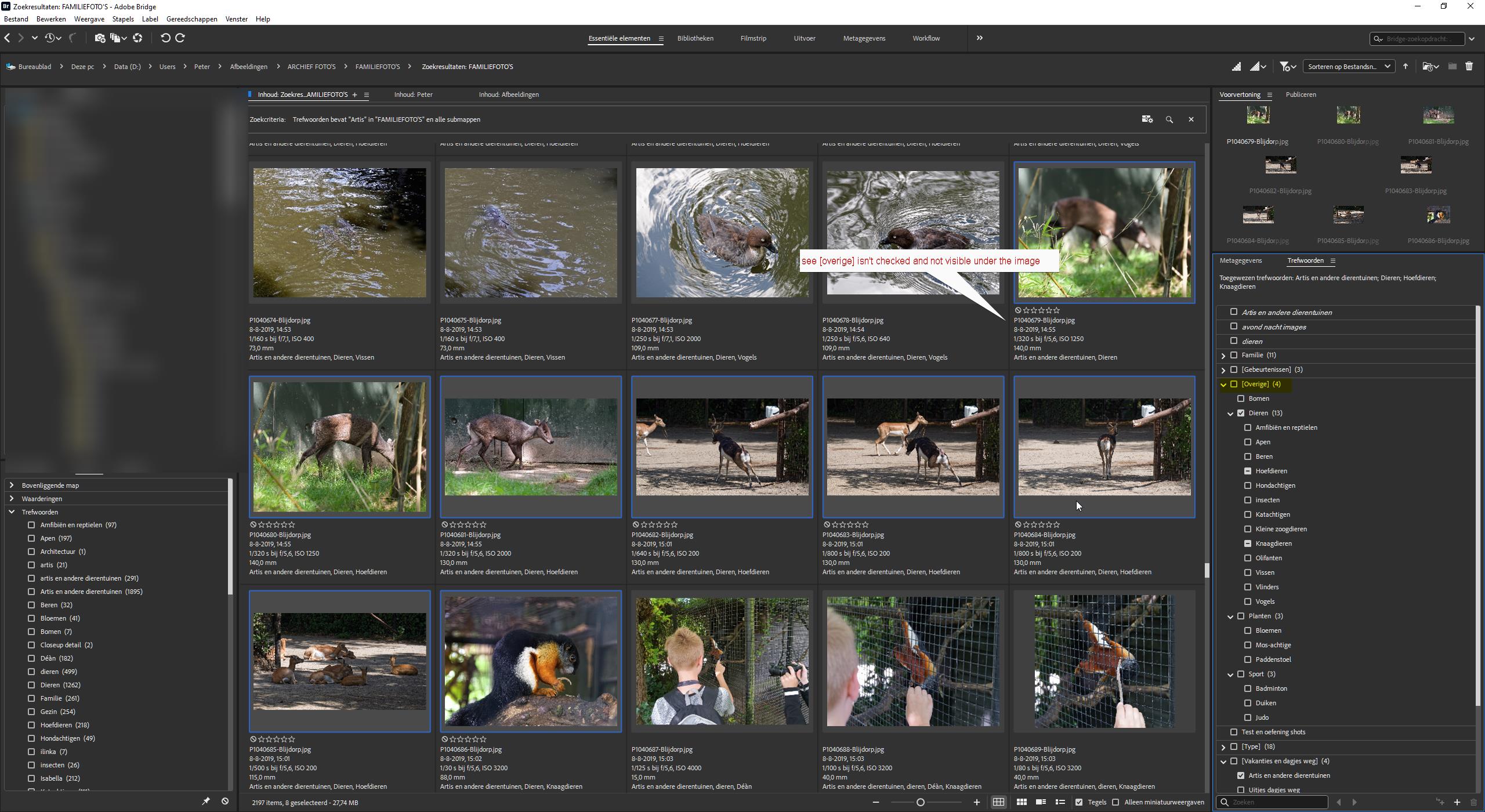
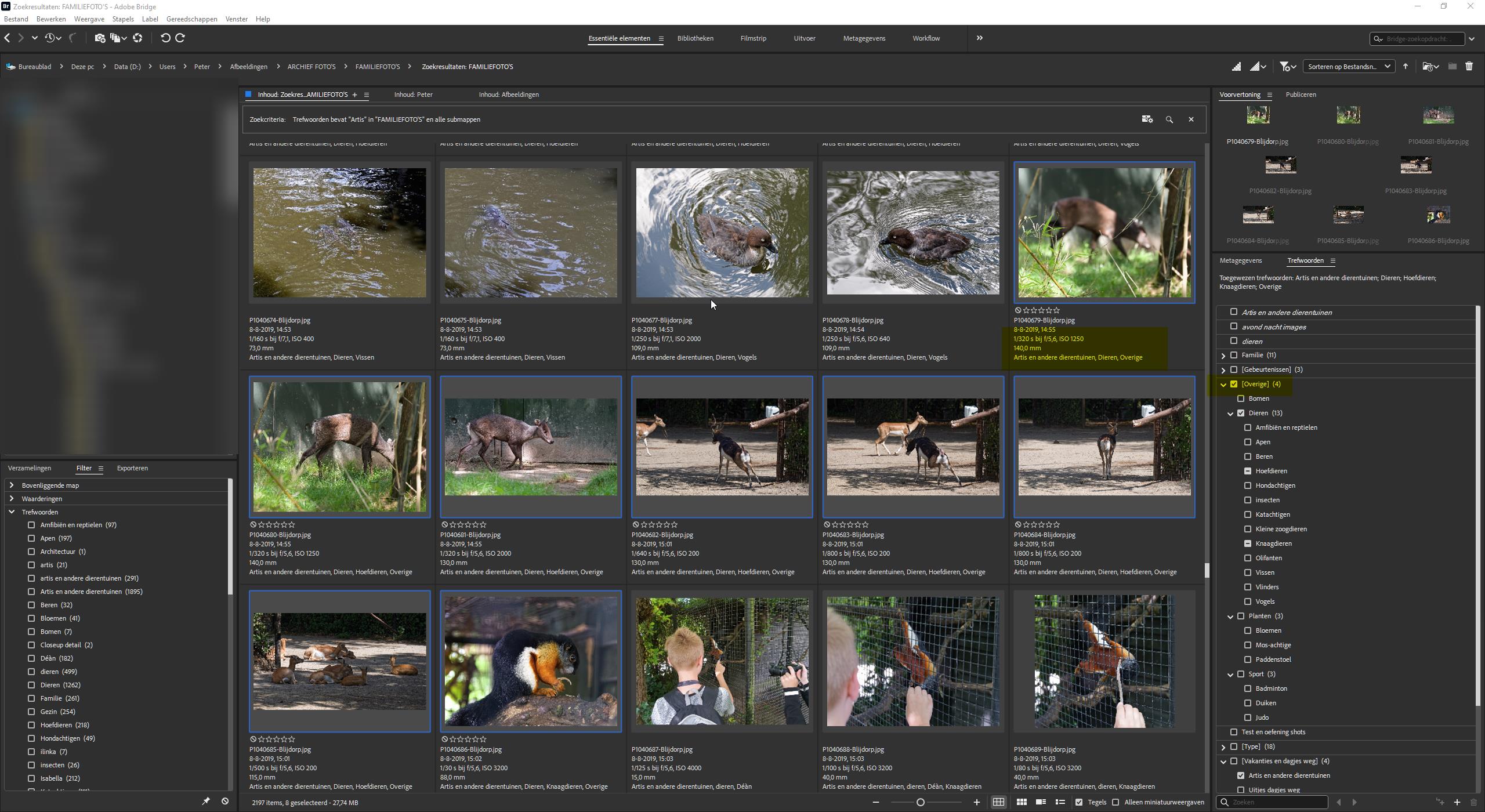
@Musashi I truly, truly …truly detest the keyword interface with drag and drop it is utter rubbish. Please provide a switch to disable it! I went to show the selection boxes for the hierarchy a|m|b and wound up with this
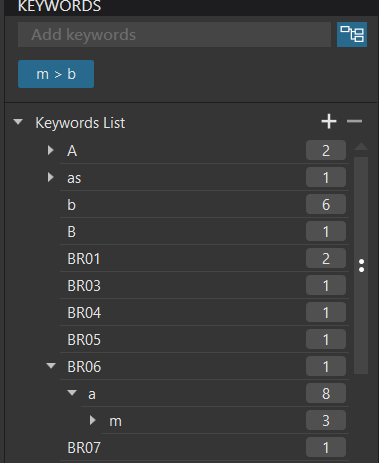
I either have a sticky mouse microswitch or a lazy mouse finger (comes with old age) and have moved the keywords to somewhere they don’t belong when I was actually trying to open the hierarchy. I have done this many times before and asked for the ability to disable that facility.!
The only way to get that back is either attempt to drag and drop or delete and re-add!!
So after a successful drag and drop @OXiDant we have
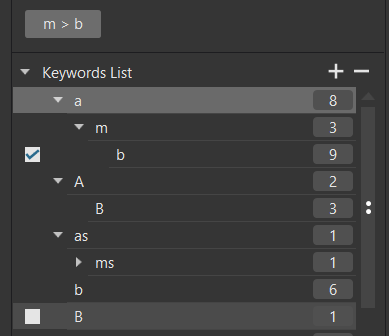
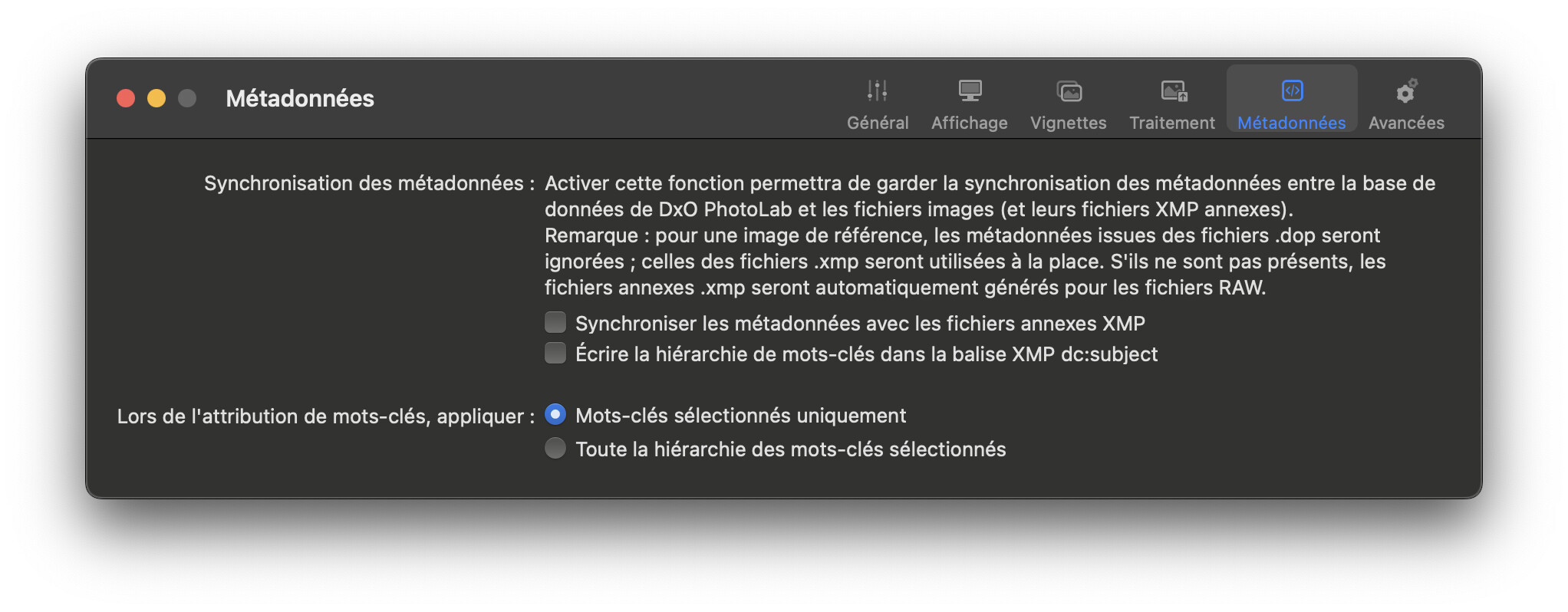
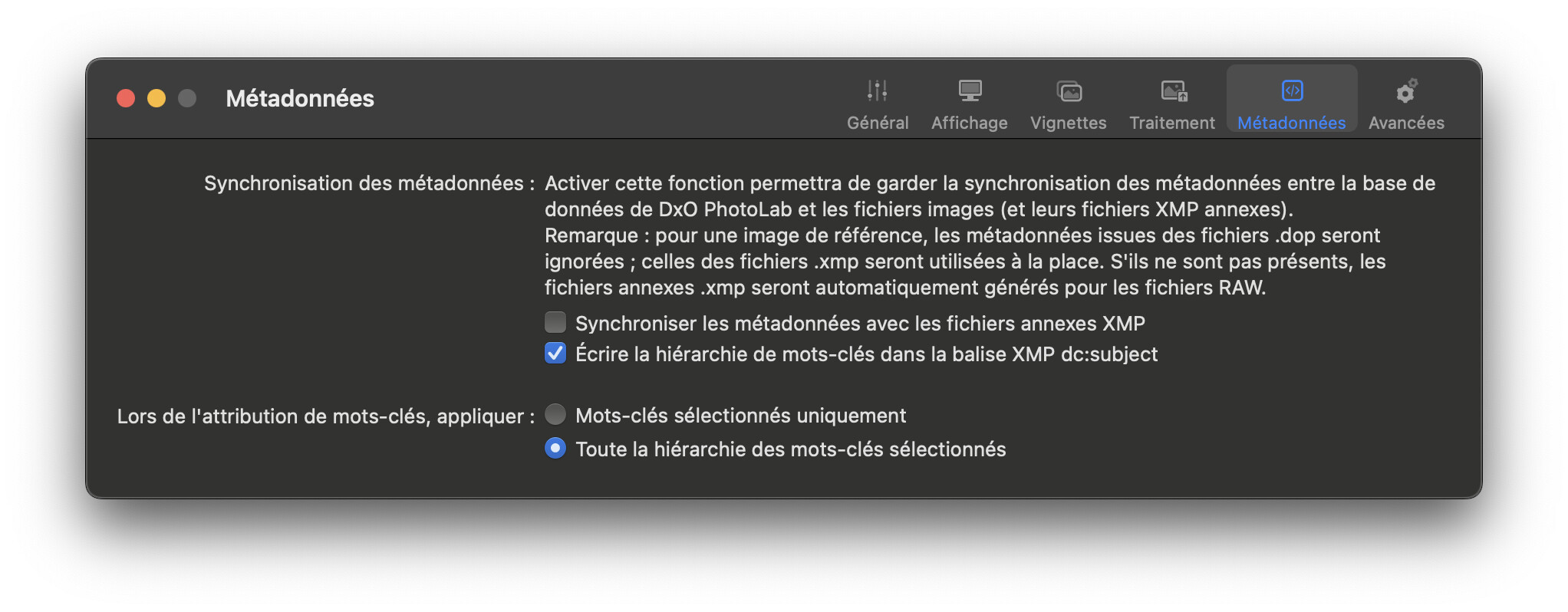
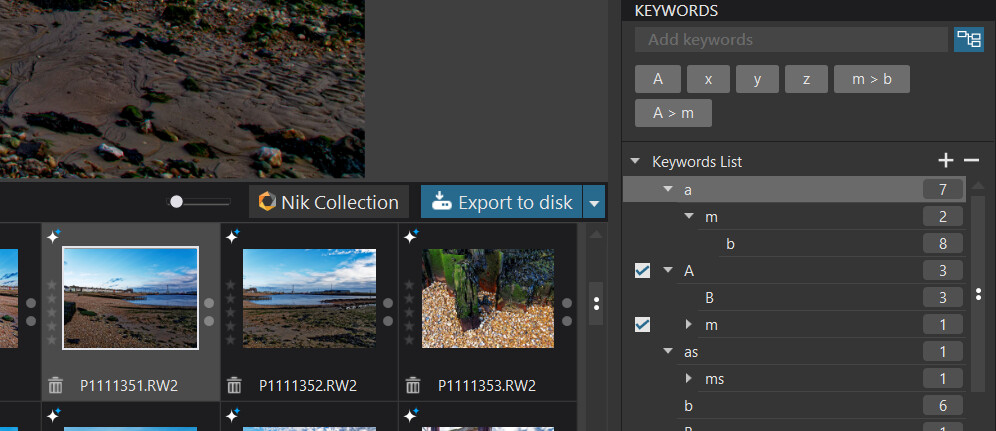
ONLY the item shown with a tick is available for searching. This was me setting option 1 and testing
Typically I work with option 2 selected and will get this automatically
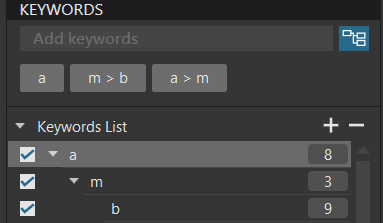
but that also means a more comprehensive range of keywords, Option 1 keywords shown in the first group and Option 2 keywords shown in the second group
[quote=“OXiDant, post:54, topic:36569”]
My problem with dxopl’s settings is if sync is off it doesn’t read metadata again every time i start dxopl in order to be up to date.
Yes sometimes it does sometimes it don’t.
[/quote]LvE1BQ3FyPYY4ckJIQ.png)
If AS(OFF) then DxPL will (should) not re-read automatically except to raise the ‘S’ icon!
There should be no “sometimes” in this and I have no personal evidence that there is but I am specifically testing certain scenarios and you are using the product for your purposes!!??
DxPL provides controlled metadata copy and export but not transfer and I have not seen commands/controls for that in any other software I have tested. It is all or nothing.
I understand that will happen but please try to show a before and after snapshot.
If you are trying to do geodata in DxPL and return that to Bridge then you are breaking the “master” “slave” relationship, DxPL is becoming “master” of part of the metadata!
AS(OFF) puts you in the driving seat nothing is supposed to leak back into the image unless you explicitly request it. You are suggesting that AS(OFF) is actually AS(OFF maybe) but that is not the way it works, to my knowledge.
Start writing to all the manufacturers and if you think DxO are tough …
It is never going to happen, hence my ignored proposal for a table driven keyword formatter.