It looks like a number of you are programmers and have done some reverse engineering of various aspects of Photolab functionality.
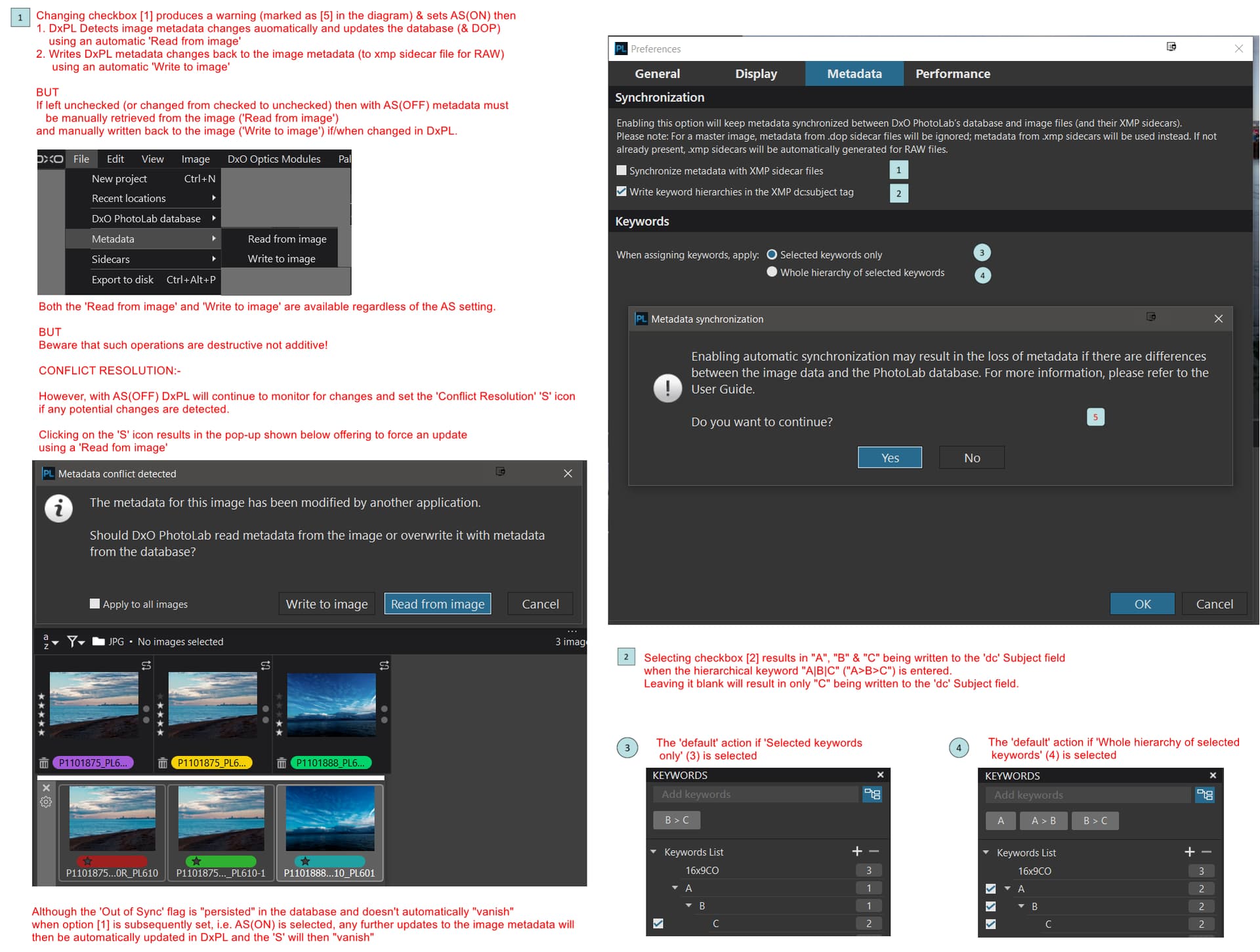
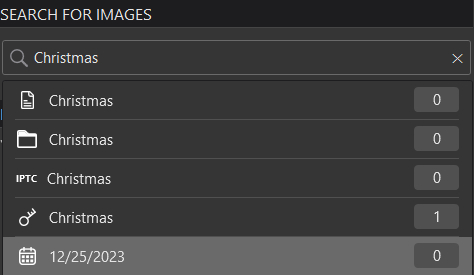
I’ve gone for years without bothering with the DxO database. I could delete it at any time without worry. In the last week, I decided to try to use hierarchical keyword feature in PL7. I enabled “Synchronize metadata with XMP sidecar files” and “Write keyword hierarchies in the XMP dc:subject tag”. Also, when assigning keywords, I set PL to apply “whole hierarchies of selected keywords”.
Before I had PL, I used Adobe Bridge to create keywords. To bring all my keywords into PL, I had it index my main photo storage folder and all sub-folders. Some of these folders are export folders and should never be part of PL’s database, but there appears to be no easy way to exclude sub-folders.
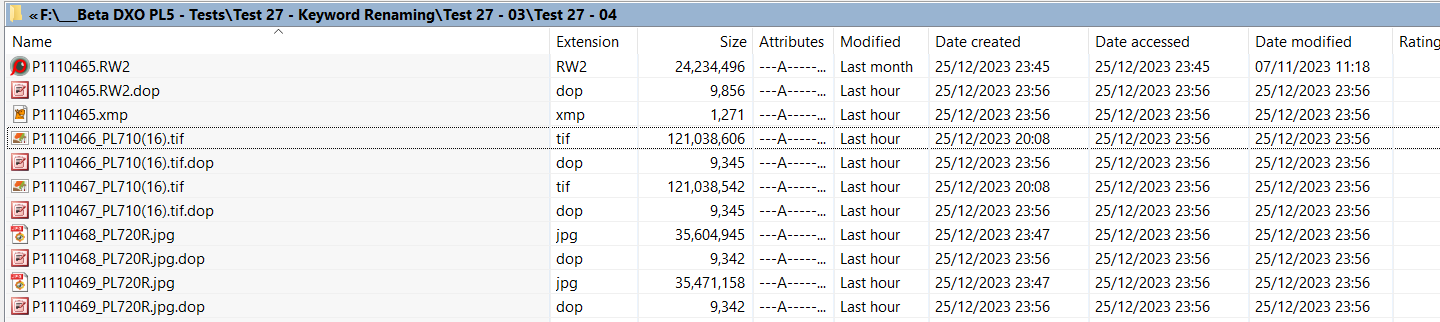
Now I have files with no sidecars, files with only DOP sidecars, files with only XMP sidecars, and files with both DOP and XMP sidecars. I am trying to figure out when and why these sidecars are created.
Here’s my best guess as to what happens. Let’s start with what happens when PL initially encounters a file:
- PL always stores some information about the file the database. I don’t know exactly what is stored.
- If the file has no sidecars, PL copies the metadata from the file into the database and applies the default preset to the image.
- If the file has an XMP sidecar, PL copies the metadata first from the source image and then overwrites it with the metadata from the XMP sidecar.
- If the file has a DOP sidecar, PL applies the image adjustments specified there, completely ignoring the default preset.
Some information may live in both the image or sidecar files and in the database. The manual hints that PL will display a special symbol in the browser when the data conflicts (at least in cases where the user asks to keep things in synch).
What happens when PL encounters the same file later? PL will have some information about the file in the database.
- If there is no DOP sidecar, the default preset is applied. If a DOP sidecar used to exist but no longer does, nothing from it is retained (this is probably not quite right).
- Metadata is read first from the image file. If there is no XMP sidecar, then metadata additions/revisions are read from the database. If an XMP sidecar exists, the database values are ignored and the additions/revisions come from the XMP file.
What causes the sidecars to be created?
- When any image adjustment is made, a DOP sidecar is created. All further image adjustments are written to and read from this DOP file. Image adjustments never come from the database.
- When any metadata is altered or added, an XMP sidecar is created. Again, I think the XMP sidecar stores only the metadata additions/revisions. The data may also be redundantly stored in the database in case the XMP sidecar is deleted.
Let me repeat that all this is a guess. I would need to do some testing to see if my guesses are accurate, but some of you may already have done the work.
I’m pretty sure some of this is incorrect. Some of my old Photoshop-exported JPGs have wound up with DOP sidecars only. These files shouldn’t even be indexed as they are exports, not source files.
Here’s what I think happened:
- To get all my keywords in the Keywords List pane, I had to index all my images. I export files into sub-folders of my source images, so the sub-folders got indexed, too.
- The JPGs contained embedded keywords back from 2019. (PL also places metadata/keywords directly in exported files).
- When I searched for images with certain keywords, these images were included.
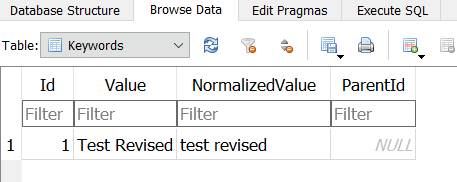
- When I altered the old hierarchy, a sidecar was needed since PL never alters a source file.
- I would have expected an XMP file, but PL stored the keyword changes only in a DOP sidecar. These are not usable by any other program. External software will still see my old keywords.
The last bullet tells me that I do not have a full understanding for XMP/DOP sidecar creation—or PL has a bug.