This might be interesting for those considering a new Mac for their DxO PL7 processing. I own a macStudio M1 and Studio display that is my primary image editing platform. This system has a M1 Max SOC (10 CPU cores, 8P and 2E, 32 GPU cores, 16 core Neural Engine, 64GB of RAM). I recently purchased a new MBP16 with the M3 Pro SOC (12 CPU cores, 6P and 6E, 18 GPU cores, 16 core Neural Engine and 36 GB of RAM). I was interested in the performance differences between these two systems. I collected 20 raw images (high ISO/Noisy) - 10 from my OM-1 and 10 from my A7RV and processed them through DxO PL7 - specifying Deep Prime XL and Smart lighting along with the standard corrections.
Here is the interesting data: It took 5 minutes 17 seconds to process on the macStudio; it took 1 minute 21 seconds to process on the MBP16 M3(!). On both systems, DxO PL7 was set to use the Neural Engine. Apple says that the M3 Neural Engine is 60% faster than the M1 - but this is a huge difference. It makes me think that I should upgrade the Studio to M3 when those become available. At this point I would strongly recommend the Apple M3 systems for image processing.
I also own the Topaz Photo AI software: Processing these same images takes 4 minutes 48 seconds on the Studio and 3 minutes 51 seconds on the MBP M3 - so there is a performance improvement there too, just not as large.
I thought I was stepping down with the M3 Pro instead of Max SOC (I wanted to save some money because I was ordering 2 TB internal SSDs on the MBP), but got a better performing system instead.
I agree that these benchmarks can be interesting (there are lots of these published on the internet) - but I find tests using “real” functions that I actually use to be more practical and useful.
Thanks @HamsterDR for the “real” world test, as someone also looking to upgrade from M1, and who owns both the software you mention this is very informative. Are you able to share the raw image sizes, both megapixels and MB ?
Sure. The 10 OM-1 raws average around 23 MB each (the OM-1 has a 20 mPix sensor); the ten A7RV images average around 85 MB each (the camera has a 61 mPix sensor). Both cameras are using compressed raw formats. The DNG output files are huge - around 250 MB for the Sony and 95 MB for the OM-1.
You can’t see it for DxO, but Topaz Photo AI shows the processing for each image - and the output process takes a significant about of time for each image. That is processing time mostly, I think, because input and output is from the internal SSDs on these systems, and those SSDs are really fast.
Make sure that your edits are the same on both machines - and that both runs are the same as e.g. first ever export. Run the same export several times to see the effects of caching. Also, the number of parallel exports can change the resulting times. I found optimal setting with exporting 3, 4 or 5 images in parallel. It’s just that 317 seconds vs. 81 seconds feels too big a difference.
I have done this test twice with almost exactly the same results (after closing the app and rebooting). The DxO configuration is the same on both machines. Both systems are set to run 8 images in parallel - a setting I have been using for several years. It is a huge difference (much larger than I expected), and I don’t think it is just the Neural Engine. One interesting thing about the M3 concerns the Efficiency cores. By default, they are set to run a a lower speed than the M1 E cores. But, if the P cores are maxed out, the E cores can speed up - much faster than the M1 E cores, and about 75% of the P core performance. Running this test maxes out the cpus, so I think the M3 E cores are used and help a lot.
Hi David
Thank you for this comparison, it will help me to choose my future M# Macbook Pro
I guess you could win more performance buying a Mac Studio with 32 neural engines
If someone has this I would love to see the numbers of the difference 16/32 NE
Yes, I did some experiments with different settings. Within a fairly wide range, it doesn’t make a lot of difference. Certainly, going above 8 doesn’t improve performance. I was looking at the number of cpu cores available - but now I think the Neural engines make more of a difference (at least for Deep Prime noise reduction). I can monitor CPU load on both systems (iStat Menus), and this task pins all the CPUs most of the time. DxO lets you choose from Auto (which selects Neural Engine), Neural Engine, GPU, or CPU. I did try CPU but that was horribly slow - I killed it after it has processed only a few images after 5 minutes. It would be nice if the app selected the processing count too.
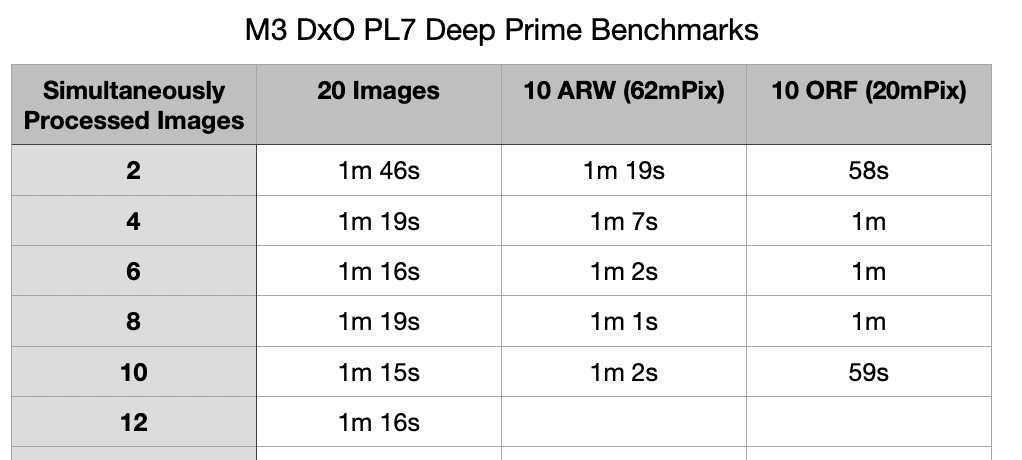
I hadn’t checked the effect of changing the number of simultaneously processed images since I was running DxO on an iMac Pro (Intel). I had settled on 8 images as being reasonable for my work. So, I did the same experiment on my MBP16 M3 and the results are shown here. I used 20 test images - 10 were from my Sony A7RV (62 mPix) and 10 were from my OM-1 (20 mPix) - which I think pretty much covers the range of sensor sizes that people will want to process. The result is once you get to 4 images it doesn’t make much difference. I also processed the Sony ARW images and the OM-1 ORF images separately - the smaller OM-1 images process faster, but not by much. One difference was that processing the large Sony images pinned all 12 of the CPUs on my MBP16; when processing the OM-1 images, the CPUs never got close to 100% load. Invisible overhead is probably involved here. I was outputting the processed images to DNG files and thought perhaps there was significant load involved - but I tried outputting to a 95% jpeg format and that was a bit slower! Obviously, this is all dependent on the images I used and my specific Mac but I do think it is pretty clear that the number of simultaneous images is not a critical setting. In fact, I don’t know why DxO even has this setting. (Maybe choosing a lower number would help when you have other big processes running at the same time - but macOS seems to manage this pretty well now.)
I see… I usually test at least 100+ raws from the same camera with DPXD NR setting and and I output to TIFF , and to exclude any SSD IO matters all raws reside on a RAM disk and all TIFF output goes to RAM disk… I have enough RAM to do that
As far as I’m aware there is little difference between the Neural engine performance on the standard M3 compared to the M3 Pro & Max (The Ultra has extra NE cores, so presumably there would be a boost there). Please correct me if I’m wrong.
I’d love to see a test like the one @HamsterDR conducted, but with M3, M3 Pro and M3 Max machines to see how they compare.
I hypothesise the export times would be similar, but the responsiveness of the editing process would be different (ie the higher spec machines have greater responsiveness).
I also suspect that the Neural Engine is so efficient with DeepPrime processing that only a Apple ‘M’ machine that has vastly more GPU cores than its own Neural Engine will use the GPU to process DeepPrime.
Thank you for the extremely insightful contribution. This workflow. is also interesting for me. I still have a Macpro Intel and I’m a little surprised at how little faster the computing process of your M1 Studio is. Because for me these exact processes run on the built-in graphics card RX580. But the card’s fans start to run properly… I’m looking forward to my new Studio M3 and as many graphics processing cores as possible for Christmas… Thanks again. The objections of others here are completely irrelevant. Your post was aimed exactly at people like me, a user.
I would be interested in another test between the two graphics configurations of the Macstudio. How relevant would something like that be? exactly with such a workflow. But I guess I’m lost there.
First thanks for the benchmarking, its of interest to me as an M1 user contemplating upgrading.
Also you said you didn’t know why DxO included the option. I suspect it’s from the days when many CPUs were single cored but a few multi-cored ones were appearing. On a single-core processor parallel processing could actually slow things down so setting it to off or 1 at a time would be better. But if you had multiple cores you could set it to as many cores as you had available and see a win. Nowadays multi-core CPUs are the norm and once you get above 4 or so parallel tasks other factors (like disk I/O contention and memory bus limits etc) start to dilute the benefits.
@albertyy1: I used an iMac Pro for several years and loved that system - especially the fact that it never seemed stressed even under heavy load - I never heard the fans spin up. That system was designed for heavy loads - not cost-effective for normal, simple work. I moved to the macStudio to move to the new architecture and I bought the Max version to get the best performance I could afford. (I have a developer friend who owns the Ultra - my reading of benchmarks indicated that was overkill.). I don’t think the M2 advanced much (my wife is using a M2 Mac Mini but I haven’t looked at that closely). The M3 really seems to have improved. In one sense, looking at the M1 vs M2 vs M3 SOC performance is irrelevant - if you are buying a new Mac these days you are going to get a M3 - Apple is moving that way aggressively. Mac Studio with the M3 is coming this year - and given these results with my MBP16 M3, that would be tempting. The issue then, is between the Pro and Max versions. My understanding is that the Pro-Max gap is larger for the M3. I have to balance cost, of course, I have been spending on getting 2TB internal SSDs - and Apple charges a premium for this. What I really want is 4 TB internal! That would make my backup strategy simplier as all my working data would be local. I now have documents and photo images split locally and on external TB drives - with a three step backup.
I’m glad this information has been helpful. I satisfied my curiosity - but it raised some new issues (as always seems to be the case).