Tom,
OK. Thanks, this makes it easier to understand/explain what’s happening.
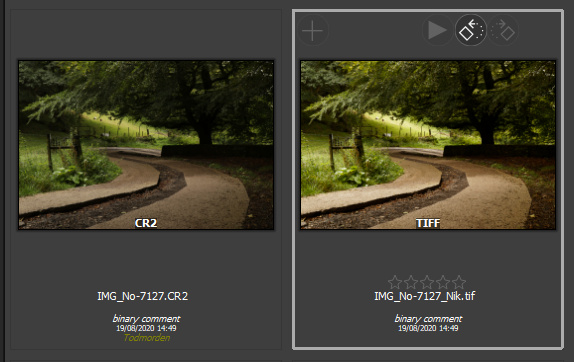
So, we have to ARW files : one coming directly from your SD card and one stored on your disk and imported by iMatch : they are both strictly identical (I have done a binary comparison). Which means that iMatch doesn’t touch your ARW files. Instead, the metadata created by iMatch are added to a sidecar file (XMP file). Since the image had already been processed by Photoshop and Lightroom, we also find in that XMP file metadata created by these programs. Normally not a problem. But…
When an image processing application adds metadata to an XMP file, it normally does this within what’s called a namespace in XMP parlance. That is, these metadata are identified by a special tag in the XMP file : the xmlns tag (xmlns standing for XML namespace). So, in your XMP file, you can see different xmlns sections like xmlns:photoshop or xmlns:lr, indicating that the metadata in this section have been inserted by Photoshop and Lightroom respectively. You can open an XML file in any text editor like Notepad to check this. It’s pure text.
So, normally, we should find xmlns:imatch tags (or something equivalent) in that XML file. This is not the case. When reading or writing metadata in XML files, most major applications use their own code. The iMatch developers don’t seem to have written code to do this. Nor they have used a specialized code library that they could have embedded in their code. Instead, for all these operations, they are using an external program called EXIFTOOL. This is a very popular free program specialized in such operations. Maybe there’s no option in EXIFTOOL to identify data with a custom namespace or maybe the iMatch don’t care about maintaining their own XML namespace but the final result, as I already mentioned in a previous message, is that the iMatch metadata are not “isolated” and cannot be identified as application specific metadata. They belong to the generic XML namespace. IMHO, this is a problem but this is not the cause of the problem you reported as I first thought.
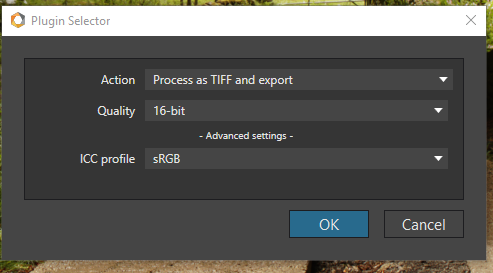
When DPL 3 is asked to send an image to a Nik plugin (or to another external application), it creates the TIFF (or JPEG) file according to the user’s export settings. It doesn’t touch the metadata already present in the RAW file and copy them to the TIFF file metadata. If an XML file is present, it also reads the contents of that XMP file and adds the contained metadata to the TIFF file.
You now have a TIFF file containing the initial metadata from the RAW file and all the metadata added by the external programs to which this image has been submitted. There’s normally no problem with this. When the TIFF file is submitted to any Nik plugin, the plugin reads the TIFF file metadata and extracts the data it needs. The Nik plugin is also able to isolate data written by third-party apps thanks to the xmlns:xxxx tags. It seems to be also able to ignore unknown metadata fields added to the standard xmlns namespace. So, nothing problematic happens.
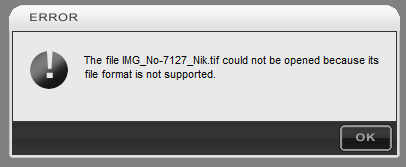
So why is there a problem with Viveza ? My first conclusion was that the metadata coming from iMatch were the culprit. But it’s not the case because just removing the XMP-tiff:compression metadata entry is enough to fix the problem. I was wrong and the answer is more simple : Viveza is sensitive to this metadata entry (which doesn’t come from iMatch) and it thinks that the file is compressed in a Sony specific format while the other plugins just ignore it. So, it just rejects the file.
So, there’s a problem at 2 different levels :
- As mentioned by George, is the non-filtered transfer of all the metadata contained in the initial RAW file to the TIFF file legitimate ?
- Should Viveza behave like the other plugins and ignore that problematic metadata entry which is not relevant for a TIFF file ?
The second approach makes it easier to fix the problem. I have posted a request for making Viveza consistent with the other plugins. The first approach is globally preferable but requires a very sophisticated analysis of the RAW file metadata. I really doubt that the DxO team will ever try to implement this approach.