Why is it hard to understand Freixas SQL and why some people that know SQL might find it necessary to use it since DXO as it is now have locked them in if they want to migrate for example. Both Lightroom and Capture One can export
I can see several cases:
-
First: As you might know there are organizations and companies using so called controlled vocabularies. They are impossible to use though with Photolab since there is no possibility to import one or export one. Just of that reason Photolab is not a serious Picture Library. I have myself once started using hierarchic keywords in PhotoMechanic just by importing one from a Lightroom-resource. The format was in TAB-separated text. This is the normal way to do this.
-
Second: Since I found PhotoMechanic like all RAW-converters or Photo-DAM (except iMatch (will explain that exception) totally hopeless in maintaining hierarchic keywords manually, the only rational way I found was to export them all from PM PLus in TAB-formatted text - editing them in Excel and then reimport them. So I guess that since it really is terrible to maintain hierarchic keywords rationally most organisations and companies using them don´t alter them if they don´t have to.
-
The need for exporting a vocabulary is that it might contain keyword structures that haven´t been used yet. So extracting them from the database records might not be sufficient right?
-
AI, yes! That is fantastically efficient when it comes to handling even hierarchic keywords BUT it can also create a total mess if you just let it run without any control. Then we comes to how to handle that because you just can´t let a tool like the Autotagger lose without a thought. That is why the developer Mario Westphal has felt it necessary to build a lot of tools and processes to harness it.
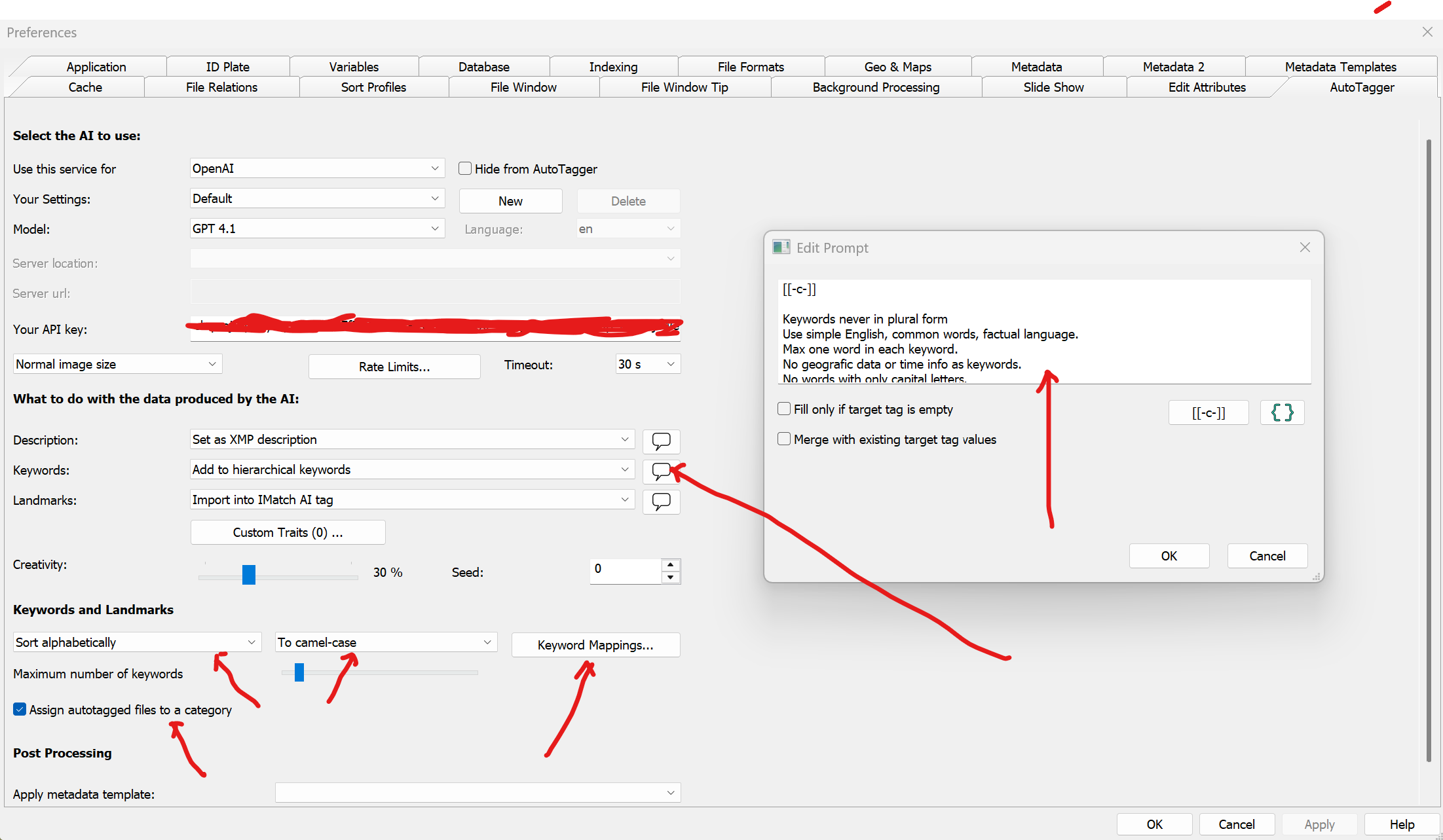
Here the Autotagger is configured:
Number of keywords are specified, formatted and handled both through predefined user interfaces and through three different AI-prompts that controls the AI-services output (Descriptions, Keywords and Landmarks.
This is how my Keyword prompt looks like:
(I have limited the maximum number of keywords above to eight.)
Prompt
[[-c-]]
Keywords never in plural form
Use simple English, common words, factual language.
Max one word in each keyword.
No geografic data or time info as keywords.
No words with only capital letters.
Write the specie of the animal, animal family name and scientific name in latin into Keywords.{File.MD.keywords}
If you cannot detect any animals, return.
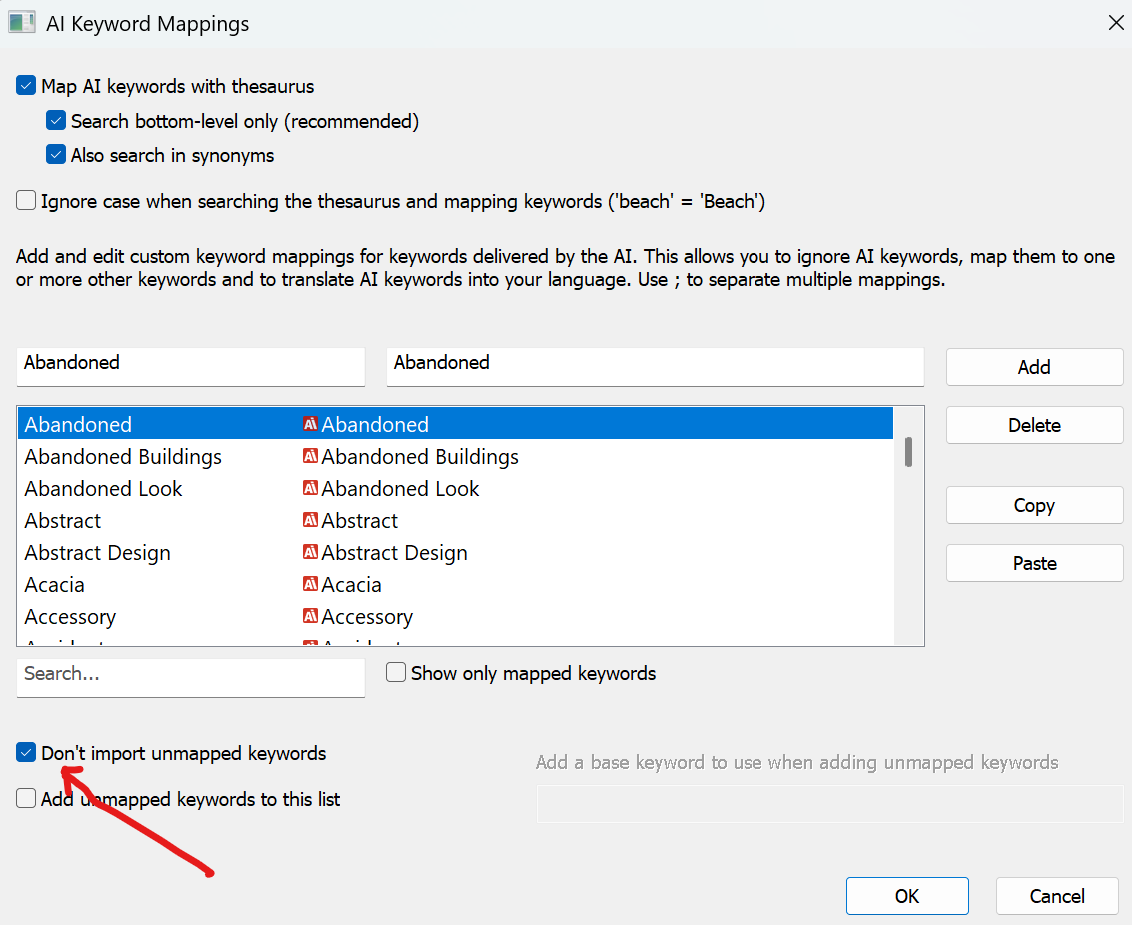
Here you can totally control the behavior of this keywording-system and how the AI generated keywords are handled compared to your active vocabulary.
As you understand these tools are pretty unique to other softwares you might have seen before because unlike software like Photolab it is built with a real “holistic” engineering where very little is falling besides or between.
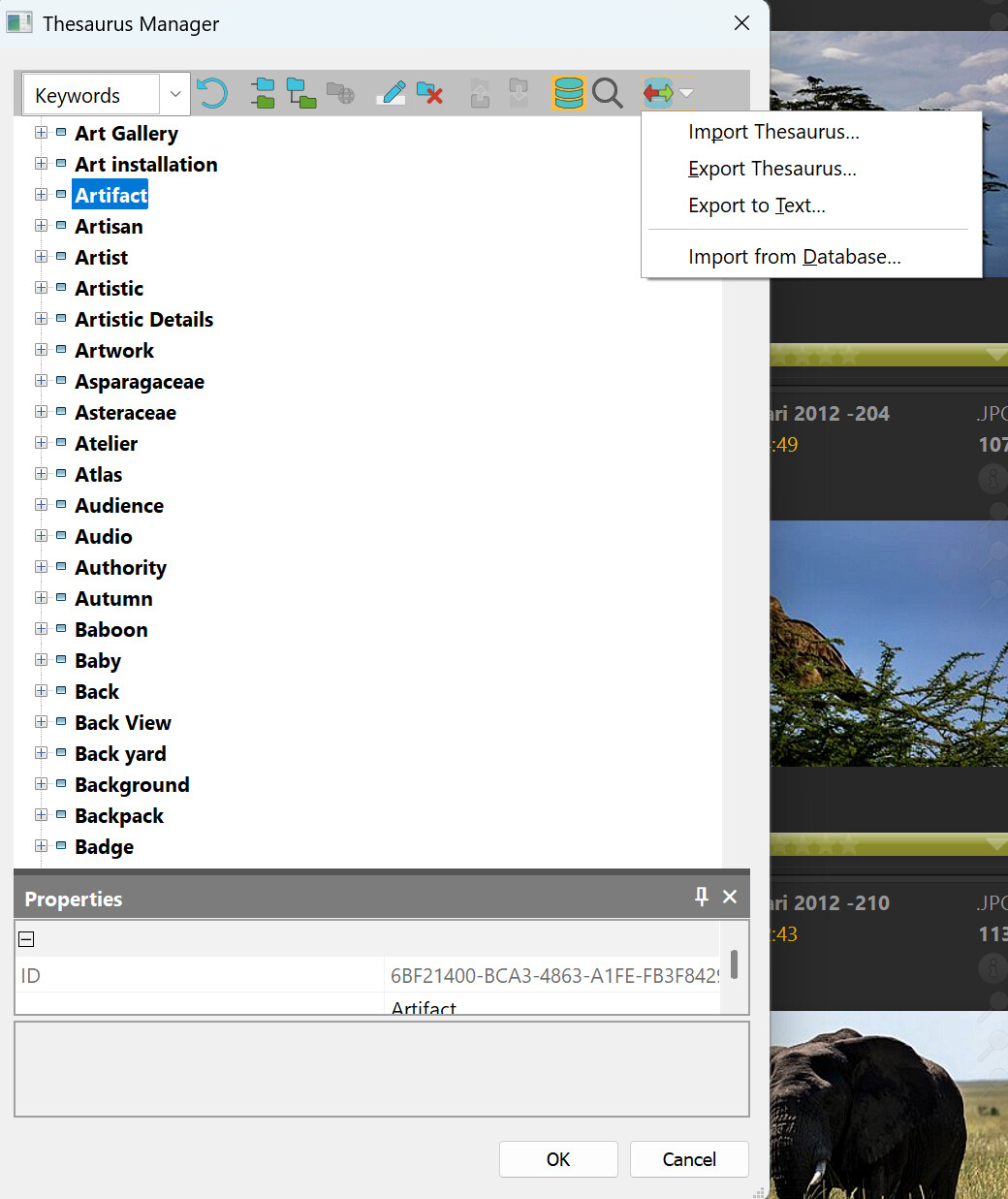
This is the “Thesaurus” or Keyword-list if you prefer that word and as you can see I don´t use any hierarchic keywords at all since I have handle that already via the keyword prompt.
As you can see there is an interface to support migration: the options to Import and Export Thesaurus. With the import from database you can import both all the plain keywords used on the pictures in the database or hierarchic ones if people use those instead.
To migrate the XMP-metadata to iMatch is a non-problem as long as it is OK for you just to let iMatch use the keywords-data that is stored in the JPEG-files embedded XMP or in the RAW-files XMP-sidecars. In that case you just import the pictures into iMatch and chose the function “Import from database”. That will build a new Thesaurus in no time based on the keywords imported to the database.
If you are lucky you can use the same way to do it even with other softwares but there are issues when it comes to hierarchic keywords in some of them. You have to chose what works for your special case in the Preferences og Photolab.
Maybe at least some people understand there are far better alternatives to use if you want to build yourselves a really good picture archive with very little effort and it isn´t even expensive! So the days when there was a need for writing SQL-queries to extract keywords from a Photolab-database or building your own keyword application are gone. It is just not worth it - unless you think it´s fun of some reason.
I´m fully convinced we will see AI-supported tools like the Autotagger in iMatch, even in RAW-converters with Photo-DAM solutions from other vendors than Photools in the future and if they are implemented they also have to take care of the keyword related problems that comes with it.