@freixas You should be aware by now of the way that the Forum works.
Unfortunately, as the author of the topic you will receive all the “traffic” that it generates, good, bad and indifferent, a fact of Forum “life”.
Yesterday (actually before your “hiatus”) I collected your scripts and saved them so that I could easily retrieve them when I wanted them, not necessarily to “protect” them
@freixas SQL Scripts.zip (5.3 KB)
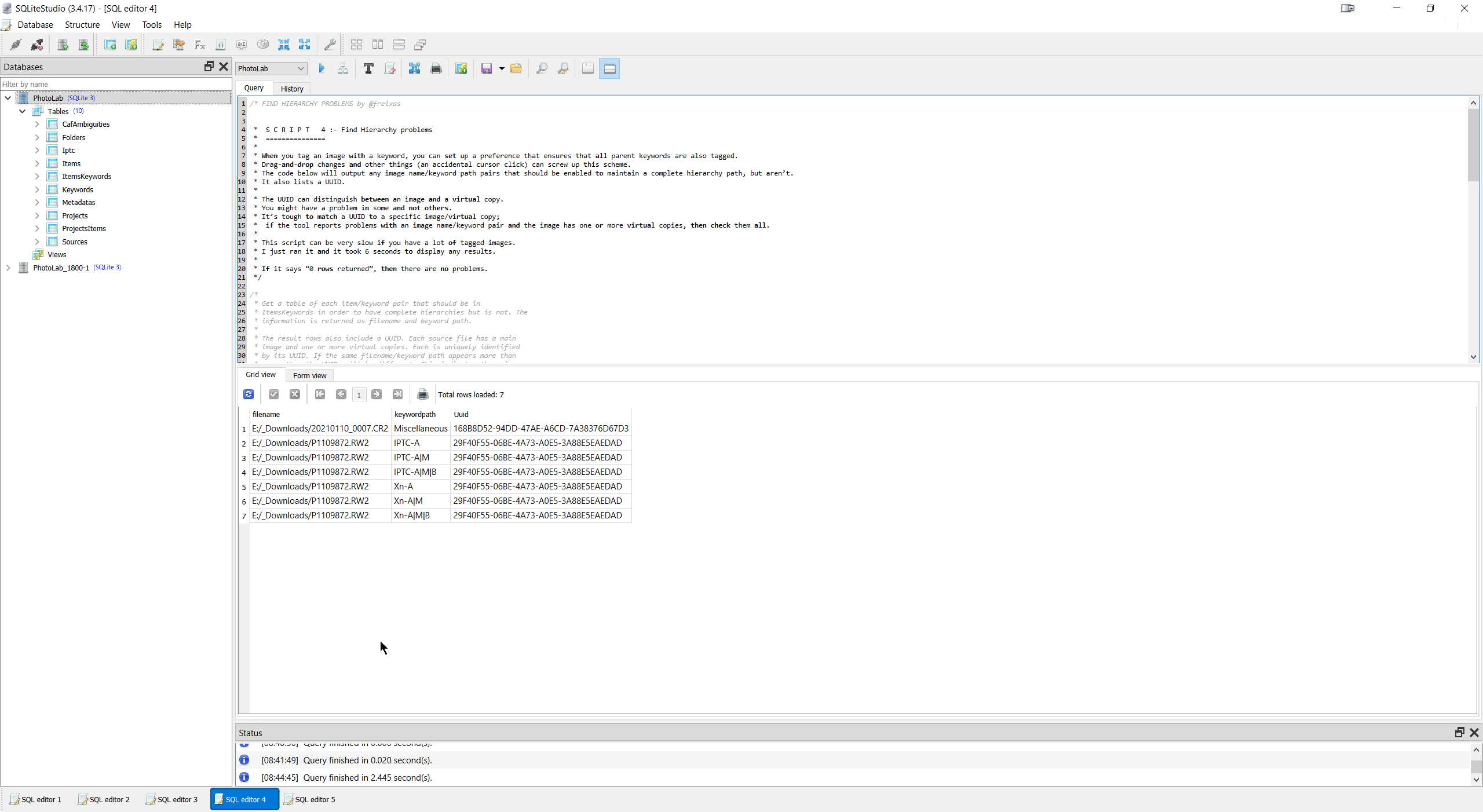
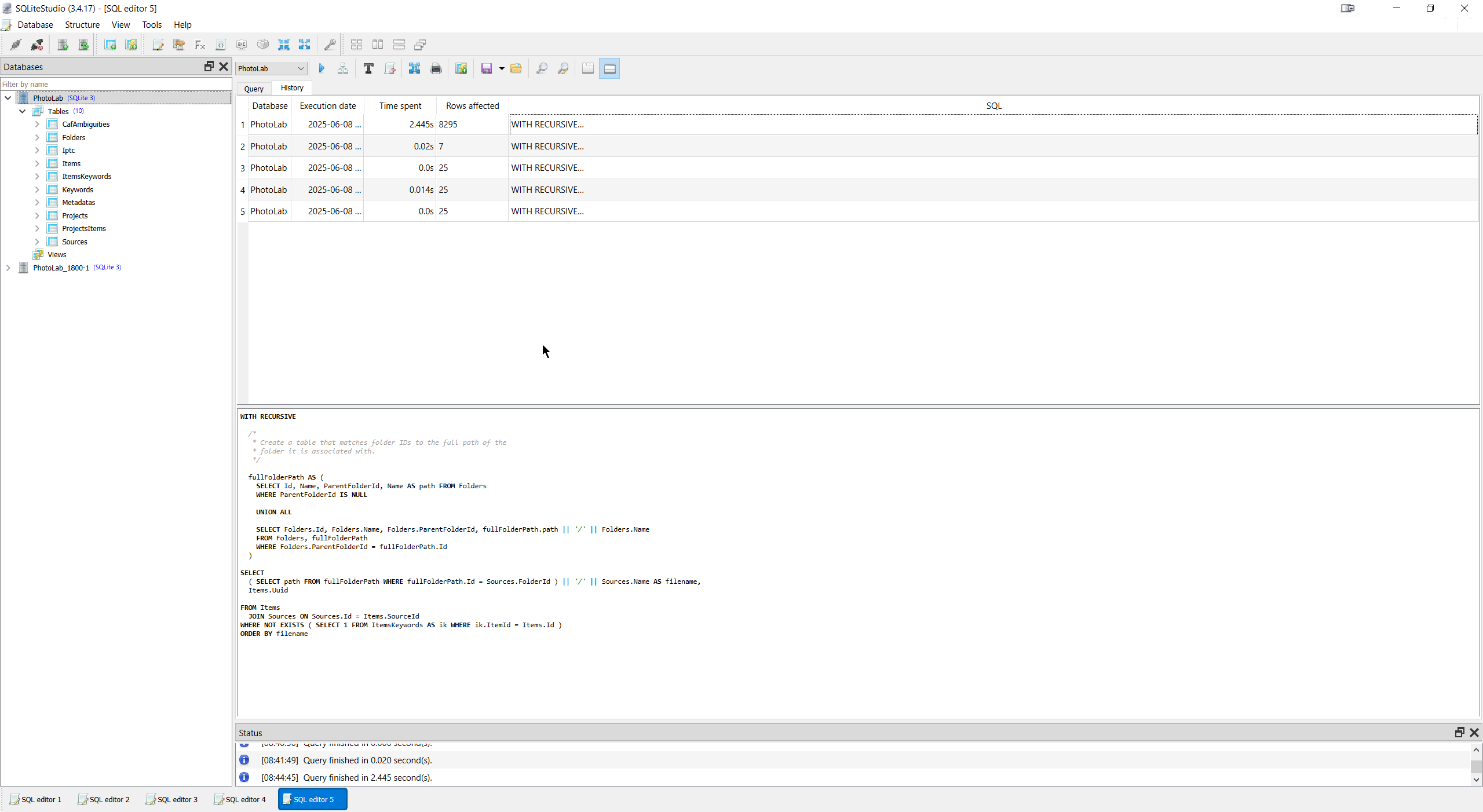
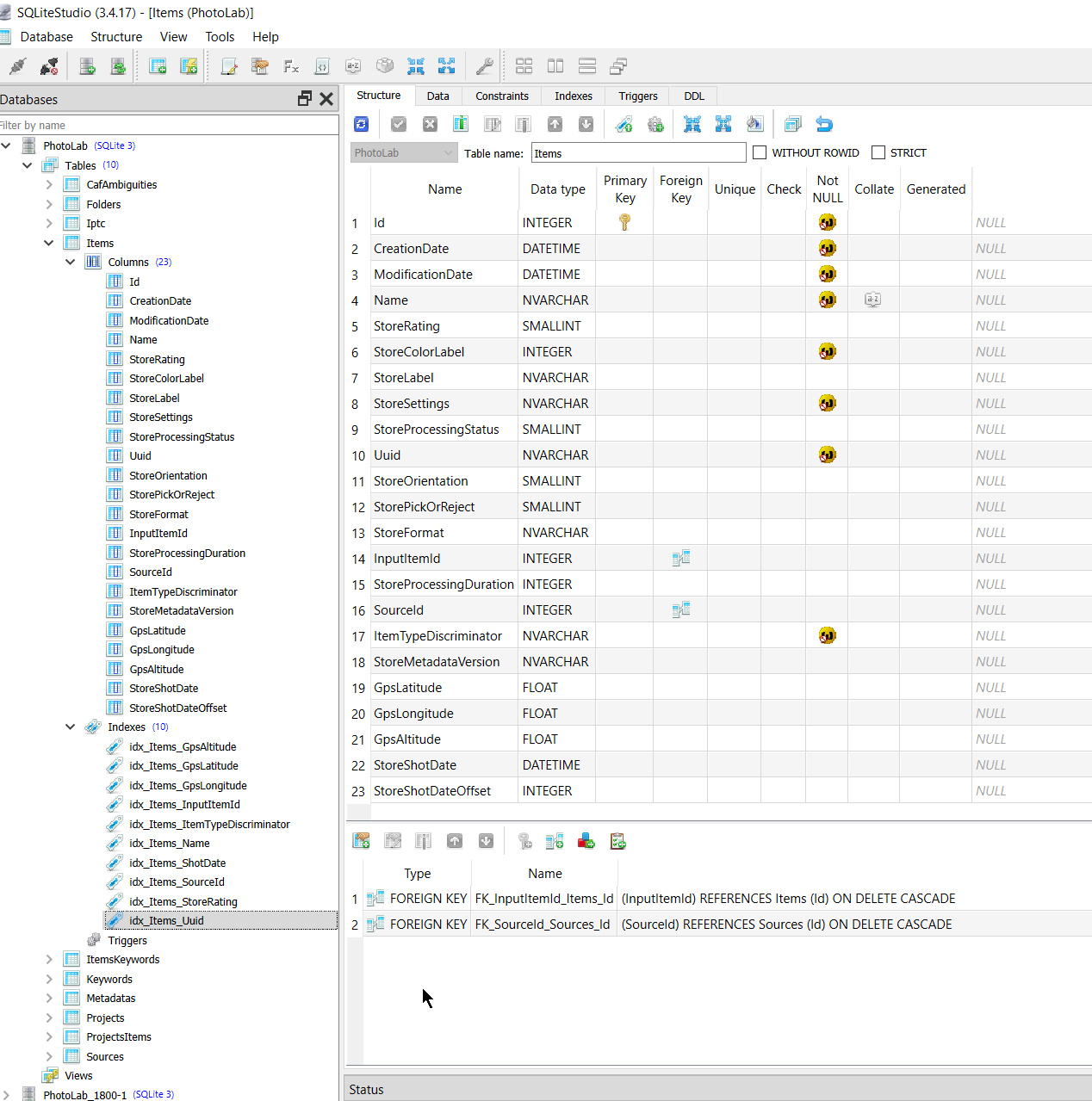
I had also found a new “toy” in the shape of “SQLiteStudio” and ran the scripts through that program one after another and I could bore you with all the outputs but I have them if required and have included the outputs from the Script 4 test and the run history summary, the latter because it is a useful component of the program
My concern with script 4 is what the output is actually telling me and why!?
The database being used is just one against which I have run numerous recent tests, i.e. I have used the “_Downloads” directory and picked up images I have downloaded from Forum posts and tested in the past, and Script 4 has detected an issue or two.
But first one comment you made in your discussion about Script 4 went something like this (taken from my file of your script)
* It’s tough to match a UUID to a specific image/virtual copy;
* if the tool reports problems with an image name/keyword pair and the image has one or more virtual copies, then check them all.
*
The statement is certainly true but what we discovered when checking data with @platypus, from his Mac, was that DxPL was almost certainly sorting the “Album” entries in the Mac DOP to re-establish the order and using the ‘CreationDate’ entry of each ‘Albums’ in the DOP.
On the PC they are all arranged in the DOP in the expected order i.e. [M]aster, VC[1}m VC[2] etc, but that is not the case with Mac DOPs but the order can be determined by sorting the ‘Albums’ into ‘CreationDate’ order.
However, there is no such index in the database and no indicator in any structure about whether an item is a {M]aster or a VC, nor what the order actually is.
In fact, I believe it is on the ‘Id’ field, which is allocated when an image is discovered or a VC is created by the user and, as far as I can tell, the ‘Id’ is an ever increasing field with no re-use of “old” numbers, i.e. the order in which the entries were added to the database, first entry for the original image and then one for each VC as and when added.
but as you stated there is actually no way of knowing whether an image is the [M]aster or a VC simply by looking at the database entry.
@Joanna The XMP sidecar is not necessarily a useful “export” device because users are deliberately stopping DxO from updating the XMP sidecar for fear of it “re-formatting” their carefully crafted hierarchical keyword layout.
That “re-formatting” of keywords into the chosen DxPL format has always been there with PhotoLab but was restricted to the Export files which users seemed happy to accept until PL5, when it was extended to “adjusting” the keyword in the image (JPGs etc. or XMP sidecar for RAWs).
However, as a result I turned my attention to the one sidecar PhotoLab users do tend to keep, namely the DOP.
As for the process of making use of the outputs from the scripts or from my DOP analysis program (the new version is still under development @RAGING_FURY) the answer lies in a bit of coding somewhere to either take the output list from the scripts and run the list through a program that submits it as a command string to DxPL or, as in the case of my DOP programs, read the DOP directly and submit the located files to DxPL in a command line.
There may be issue with the number that can be passed at any one time, i.e. in the past I have managed up to 350 images at a time but the program can pass any number as a group of 300 at a time again and again and …
@Joanna As I have stated above, the DOP contains both metadata (including the ‘Pick/Reject’ flag and edits, much to the chagrin of many users, you in particular because it well and truly breaks the SPOD rule.
The “risk” is that the (latest) XMP sidecar file may not have been “absorbed” into PhotoLab, automatically or manually, but my program could easily be enhanced to interrogate the XMP sidecar file just to be on the safe side.
Any PureBasic program creates an exe file on Windows and any user could take the symbol file and compile it using the free version of PureBasic providing it is less than 800 lines long.
I am prepared to supply both if I decide to “publish” anything!
I want to avoid using ExifTool if possible, simply because of the added level of complexity right now, and your product would be off limits because it (potentially) pushes the metadata into the RAW image etc.
However, the Mac is off-limits anyway, for me at least, because I don’t own a Mac computer
Weather is looking OK. so no coding till later today or tomorrow…