When you have spent two years trying to fathom the depths of metadata, it is impossible to think of it as “simple”. So many different standards, some of which are now incorporated in other standards, some of which have been dropped. No, if there’s one thing you cannot say about metadata, it is not “simple”.
Maybe for you, but there are many photographers out there that do not require expensive, enterprise level, metadata managers.
Or, more correctly, the convention that you wish to adhere to.
macOS provides a free, efficient DAM. It provides Finder Tags, which can be added to files, no matter what type or even if they are folders. The Spotlight mechanism efficiently and unnoticeably indexes them in the background and can search for files that match hundreds of different attributes in an instant. The tag metadata even transfers with the file from one computer to another.
Unfortunately, the world doesn’t run entirely on Macs. It has only been in the last couple of years that Windows even started to get an integrated metadata indexing and search functionality. And, of course, it had to be implemented differently.
I don’t know much about the Windows metadata capabilities but the Mac system modifies the metadata in the attributes part of a file and has no need of an external sidecar.
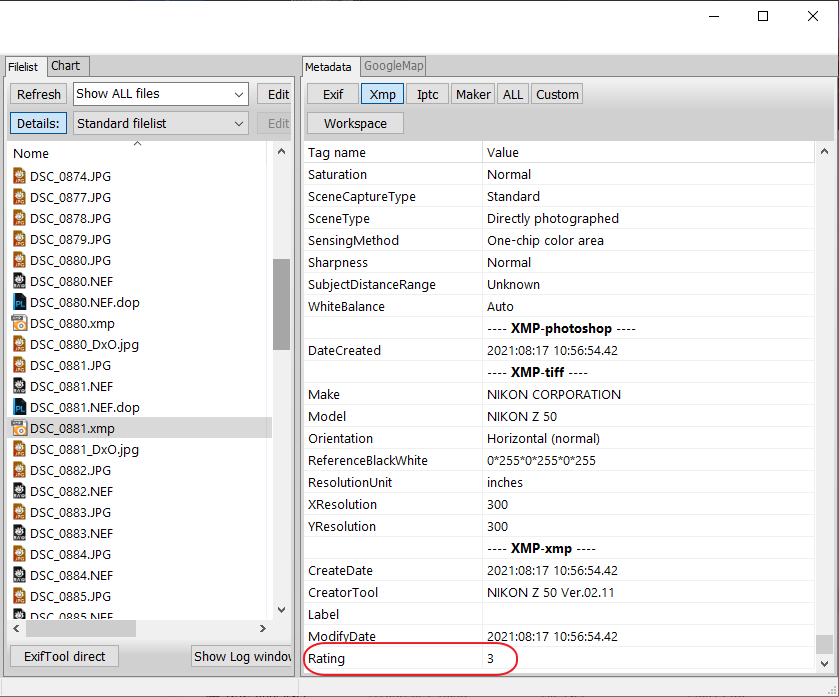
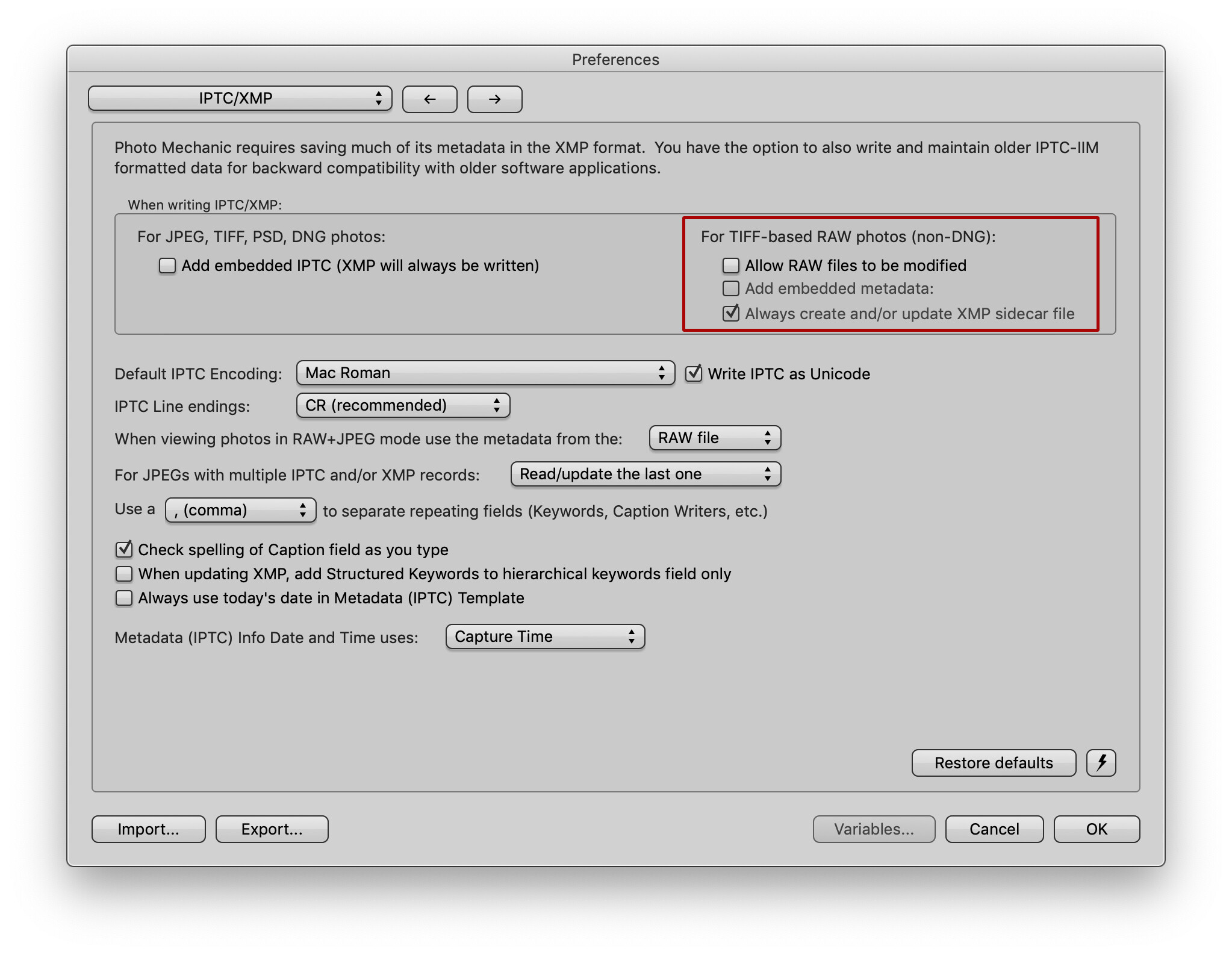
The problem with XMP sidecars is that it requires a management app to maintain the link between the sidecar and the original file, otherwise, you have to search for stored metadata held in sidecars and then further search for the related file. This is highly unwieldy and inefficient, and is the reason why most DAMs use a database to maintain some sense of sanity and speed when searching.
Unfortunately, this now makes for multiple sources of truth, where it is possible for the metadata in XMP files to become out of sync with that held in the database of whichever DAM was used to originally index it.
All it takes is for someone to change the metadata in the XMP file outside of the DAM that created it and you now end up with four possible “sources of truth”: the originating XMP, the originating database, the modifying database and the modified XMP. But which “truth” is “the truth”?
If the whole world were to read and write metadata directly from/to files, this reconciliation nightmare would disappear overnight.
If I were conspiracy theorist, I would postulate that Adobe deliberately invented sidecar files for the sole purpose of ensuring it was impossible to manage metadata without using their DAM, and the whole world fell down and worshipped the words spoken by the great god Adobe and, dutifully, fell in line - thus creating the mess we have now, where even Adobe themselves have changed the standards over the years, including now having two different ways of laying out the contents of XMP files.
Adobe themselves allow for options as to how hierarchical keywords can be written to metadata tags, for which, the default is different between Bridge and Lr.
No. metadata is not “simple”. Which is why my app (which you dare to call “hobbyist” without even having used it) doesn’t use a database, because it relies on the single source of truth of what gets written to files and users have a choice of writing to RAW files, if they wish, or XMP if that suits them better. Either way, what the app sees and edits is always the original metadata - never a cached version from a database. It relies on the superb metadata engine that Apple has perfected over many years for storage, editing and searching. As long as other apps comply with the XMP metadata domain, my app can read their metadata and any app can read and correctly interpret, and search for, the metadata my app writes.
I am not writing them to non-standard places. My app complies 100% with XMP, MWG and Dublin Core standards. Of course, they may not be standard to your definition, but every other app out there seems to cope perfectly, even if the original metadata was written directly to RAW files.