@jch2103 I was about to comment on your statement above (some days ago) but fixing and re-lagging all the pipes of the central heating and re-testing all the scenarios got in the way!
I was going to state that the the topic ‘Unwanted Virtual copies’ ran from December 2020 to December 2021 but it actually only “racked up” 92 posts and we have exceeded that “somewhat” in a much shorter space of time, oops! I understand your concerns about the number of posts in this topic (my “central heating” references simply add to the “clutter”).
I understand your concerns and it would be useful to have certain features made optional providing PL5 can then interwork successfully with other products, indeed those options may well be related to such interworking. DxO see Lightroom as their role model and seek to ensure compatibility or so it seems.
@jch2103 and @Joanna
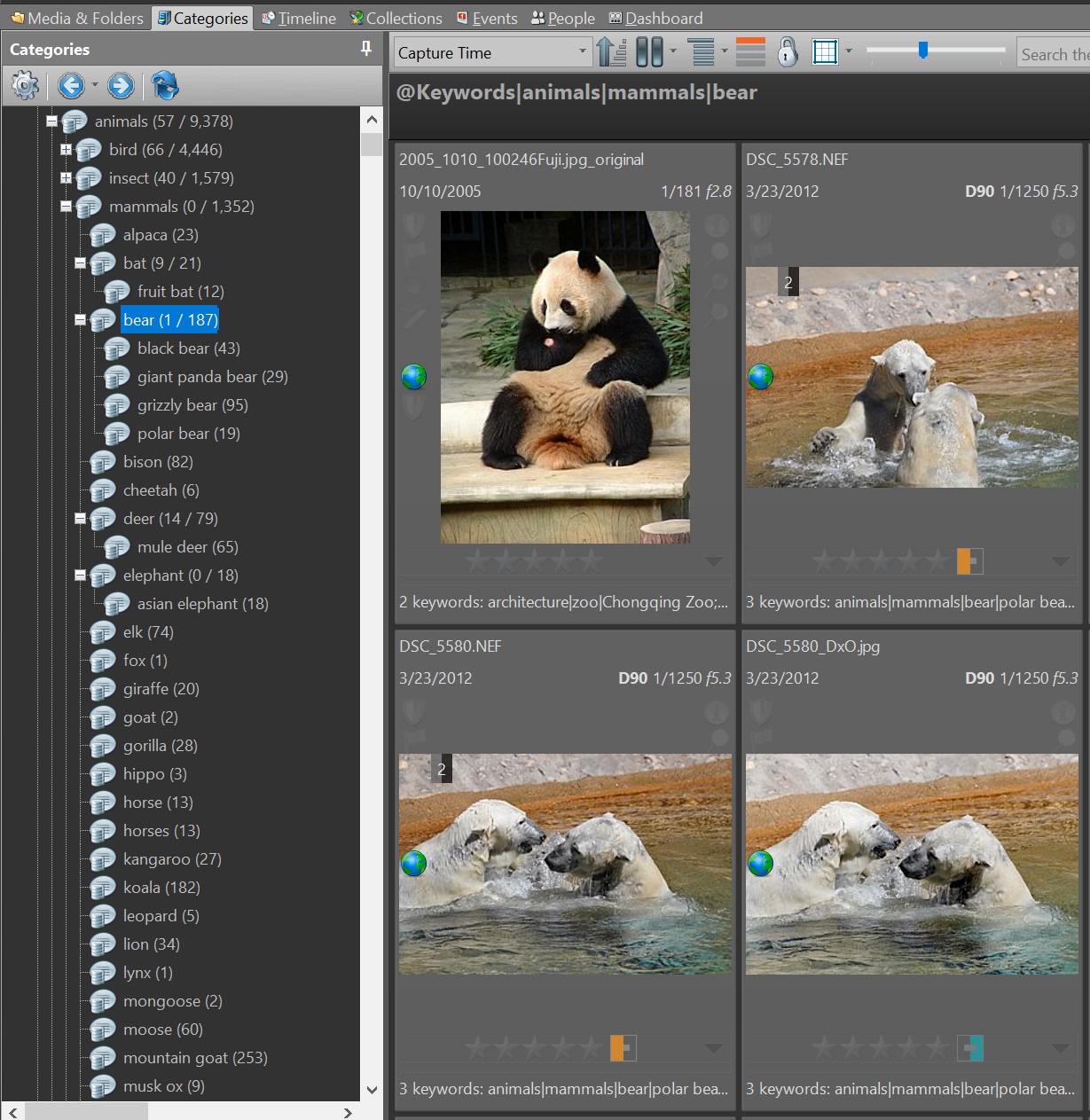
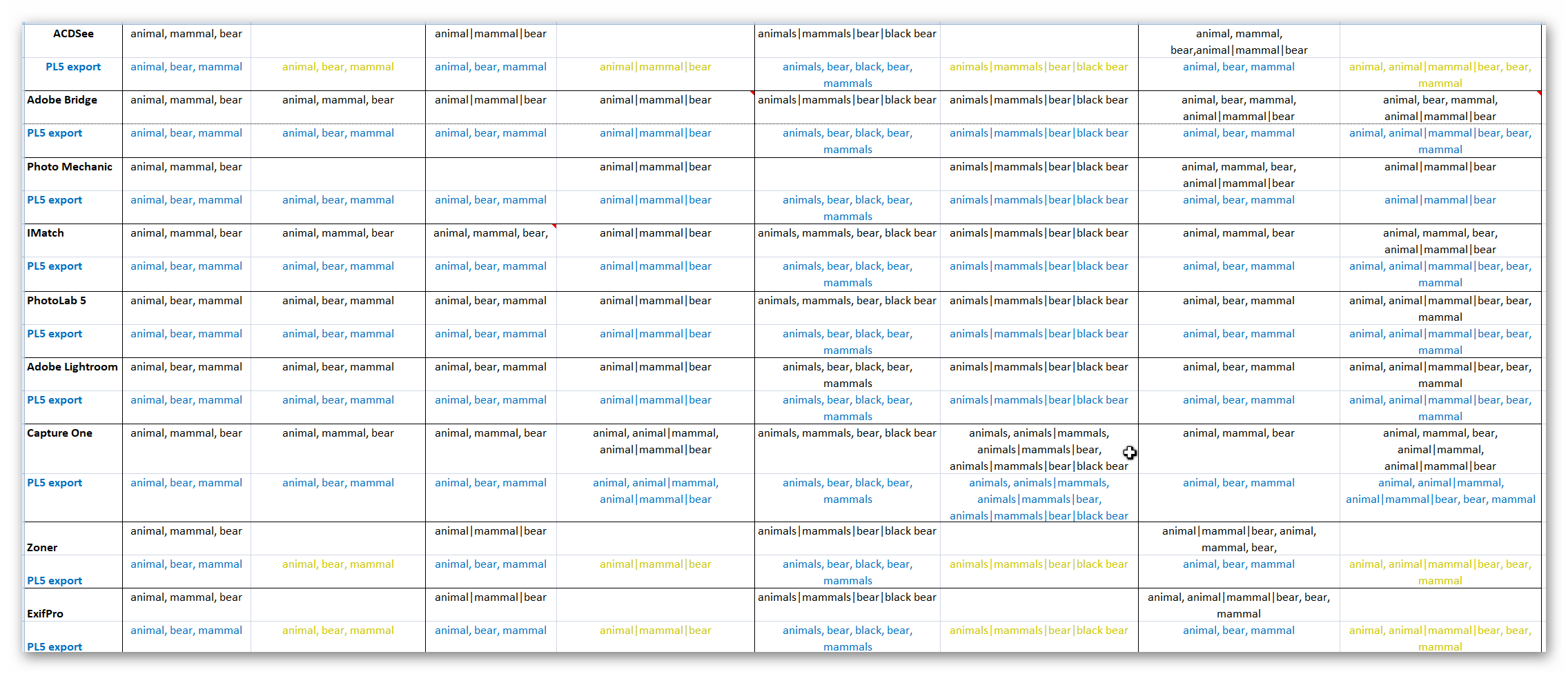
I have redone the whole of the spreadsheet again and added rows for ACDSee, Zoner and ExifPro (which works fine with PL5 for RAW images). All images are now RAW because reviewing ‘xmp’ sidecar files is quicker than getting to the data in JPGs, however I then re-discovered PIE and that simplified things further!
The discussion of the merits of IMatch versus Joanna’s program is sadly academic for those of us using Windows 10 (or 11) systems and vice versa for Mac users, IMatch is Windows only and Joanna’s program is Mac only. However, describing both has merit with respect to others on the forum who are looking for such programs and, possibly/hopefully to DxO with respect to their own (further) aspirations in that direction.
However, I do have two major concerns in this whole issue;
- Many of the low/middleweight photo editing packages are still essentially IPTC oriented. For RAW this means that they only look at and populate the ‘dc’ Subject data with their (IPTC) Keywords. They are completely “blind” to ‘hr’; Hierarchical Subject data!
- This is related to item 1 and my concern about the “high jacking” of the ‘dc’ Subject field as the repository for only the flat elements of hierarchical keywords and flat keywords themselves. This is effectively “deprecating” an existing capability, namely that the ‘dc’ Subject can be populated with keywords that have an hierarchical architecture but should not be used for that purpose any more!
In the spreadsheet there are entries in a difficult to see, dirty yellow colour which IPTC oriented software such as ACDSee, Zoner, Bridge (when I was populating the IPTC keywords in previous tests) etc. will never be able to see at all.
Others on this forum have stated, in past posts, that they use ACDSee or Zoner, it is possible that they have never even considered using hierarchical keywords with those products (me for one) to describe their images since no major advantage accrued from doing things that way, but it was a feature of the developing standards that has been “conveniently” highjacked!
I apologise for my previous errors in transcribing the data to the spreadsheet and @platypus’s comments about his approach being more accurate was correct but would have led to an even more complicated spreadsheet than the one I have now got.
I highjacked Test 3 for the animals|mammals|bear|“black bear” test (I am still sure that should have been animals|mammals|bears|“black bear” or animal|mammal|bear|“black bear” but life is way too short for that type of discussion!!)
The intention of the test was to investigate how different packages populated the ‘dc’ and ‘hr’ fields in response to a small number of different scenarios and then investigate what happened to that data when passed through the PL5 processing pipeline and exported!
The variants on this theme would be to take PL5 outputs, both keyword updates (synced or explicitly written) plus exported JPGs etc and use that data as input to your favourite editor/DAM etc. The tests are easy and quick but the transcribing is …
In each row of the spreadsheet the output from the package is shown in black and the results from the exported PL5 JPG shown in blue (or dirty yellow for those where the original software will simply be oblivious to its existence), i.e. the baseline outputs are copied to a test directory and PL5 navigated to that directory and used to export JPGs. Many cells contain the same data but the order may be changed.
The attached spreadsheet has jumped from version 04 to version 06 with version 05 retaining the old layout as well as the new as sheet 2; version 06 dispenses with the old layout completely. All the normal caveats apply, I might have left an option off in a program, I might have made an error in transcription etc. Copy of meta data setting _06.zip (13.8 KB)
Please notify me of any errors and if possible add a snapshot of your settings for any given application if you think that they are applicable.