I’d like to request the ability to batch more than 10 images at a time. My Mac Studio has far more compute power than is being used doing “only” 10 at a time - it’s nice to be able to zip through more photos quickly while cranking on a batch, but could we be given the option to go with more in parallel? It would be great if the batch subsystem could make its own determination from the system specs to see what is ‘best’ for a given system and make that a recommendation - with the ability to go more or less depending on what else I’m doing…
Hi,
Basically I agree with you: use all the power of the machine BUT let the user balance this power according to his/her needs.
I wish the UI would be more responsive WHILE I export some pictures so I can work like normal AND export or at a lower pace because my computer is old or at high speed because my computer is a workhorse.
The processes needs more separation and more user inputs.
@Bold_Studio don’t forget to vote ![]()
@m-photo thanks for the reminder!
A system that automatically adjusted processing speed to available headroom would be very welcome indeed. I had to alter my workflow on my older machine to not do any processing while I was editing because that would bring it to its knees… this new system doesn’t do that, but it seems underutilized now.
Interesting. Do you mean when the preference is to process 10 images simultaneously, all CPU cores aren’t maxed out?
How many cores do you have?
My 8 core (windows) machine maxes out CPU cores when I process 2 or more images at once. I usually just leave it set to 3… or if I’m wanting to continue editing after starting an export I set it to 1.
@MikeR - this system has 10 CPU cores (8 big and 2 ‘efficiency’), 32 GPU cores and a 16 core neural network co-processor. 10 at a time does not slow this down, or even make the fan spin up (and because of a sub-optimal monitor, I’m getting ~8 second times per image). I’m not processing on the CPU, at least by the system setting.
As I write this, I’m re-processing some images to get some live stats.
CPU overall utilization: 4-8% with 67% peaks (it seems to be waiting on something else). The chart looks like a saw tooth, with large idle gaps
GPU utilization: 0%
Neural network - I can’t say, as it’s not reported in the utilization screen
Memory: 41-42GB (I have 64 on this system), though Facebook and this DXO page are using almost a GB per page each.
I see 10 processing threads right now, and only one of them is taxing the CPU at any given time. In the length of time it took me to write this (minus the first paragraph), PL6.6 has processed 45 images in 6 min 45s. There are still a few more to go, but you get the point. 49 images in 7min 4sec and this batch is done (with DeepPrime XD selected).
Here is one:

Your GPU image is no zero. Probably your CPU utilization is low waiting for your GPu to finish. Not sure how it works on Mac but GPU utilization usually shows 3D acceleration only. If your GPU is busy doing compute activities it doesn’t show up.
Here is the definitive test. Time how long it takes to process 100 images with 10 at a time. Then reduce to 8 at a time and time the same 100 images. Reduce to 5, reduce to 3, try 2 and then try 1. I suspect you get very similar times at 3,5,8 and 10…
1 Like
10 at a time: 49 images in 7min 4sec (8s 673ms per)
8 at a time: 49 images in 6min 48sec (8s 327ms per)
6 at a time: 49 images in 6min 44sec (8s 245ms per)
4 at a time: 49 images in 6min 44sec (8s 245ms per)
2 at a time: 49 images in 6min 43sec (8s 224ms per)
and finally
1 at a time: 49 images in 8min 1sec (9s 816ms per)
your suspicion is correct, though why 1 image at a time would take longer is a bit strange- perhaps there is some opportunity cost in going from one to the next if you have to wait for one to complete? It does look like 2 is optimial, but not by much.
I think 1 image at a time is slower because the DeepPRIME work is done exclusively on the GPU and the rest of the work is done on the CPU… so because only one image is being processed, when the CPU is working on finishing the image after Denoising, your GPU IS idle. When two images are processing simultaneously, your GPU is Denoising the next image while the CPU is processing the first one.
A processing pipeline if you will.
That makes perfect sense.
What doesn’t make sense is why they can’t do this ‘better’ across all the cores and available memory.
SOMETHING is always going to be the limiting factor. In this case it’s the GPU. So the cpu will be idle at some point waiting for the GPU. The only real way they could max out both the CoH and GPu would be to send DeepPRIME processing for every 8th image (or some number) to the CPU instead of the GPU and while this is possible it’s not practical and I would suggest also not desirable. Anyway there’s not that much to be gained while doing so.
Mike - I agree that SOMETHING should be the limiting factor.
But, in my case, it’s not the GPU, nor the CPU. The monitor built into MacOS does not show neural net utilization, but it’s pretty clear that (when doing DeepPRIME XD processing) that neither are maxed out.
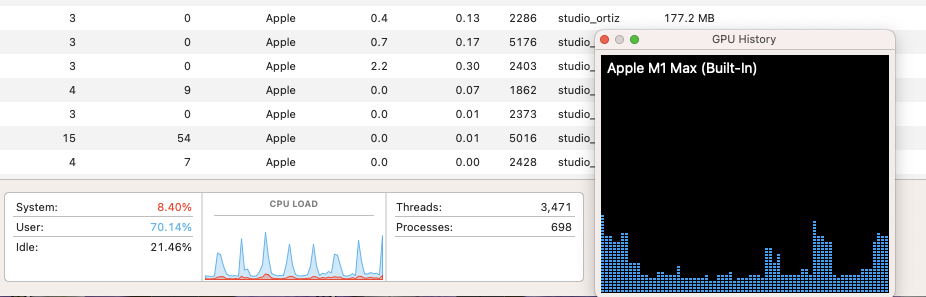
The GPU is likely maxed out. Even if it’s not showing in the chart.
I don’t have the tools on this machine to be able to say one way or the other
And you will make yourself ill trying to. You have an extremely powerful machine in every regard. @MikeR ’s real world test with actual images, processing n at a time and a stopwatch will find your sweet spot - there’s so many different things in play you’ll run yourself ragged trying to find a single bottleneck, if you ever do
1 Like
It turns out that my day job has to do with analyzing performance, but on a different platform, so while many will run themselves ill, it’s something I do to earn a living. Photography is my second income and passion. But, it’s something I do to relax and express myself artistically, so digging down into the minutiae of performance blocks on a relatively new architecture is something I’ll save for a different day.
In the meantime, I’m happy with 8s for XD processing, and the test Mike had me run did show that from a time perspective, 2 at a time seems ideal with this current version of PL. It really looks unoptimized, but again, I don’t have the analysis tools on this machine to really dig into it, but I hope that DxO does and that they spend more time looking at concurrency and how they parallelize the work as at least at first blush, for XD processing, the CPU is idle a significant part of the time, and the GPU is not heavily loaded. Because version 6.6 uses the neural network in this system, I assume that this is where the bottleneck is, but I cannot see if all of the NN engines are in use simultaneously (they should be) or if the suggestion to use a GPU or three for every ‘x’ images can result in speeding up large batches.
So - my request really still stands, but perhaps I should reword this a bit to something like: Help improve large batch operations by optimizing performance, including better load balancing across the various compute engines in a system.
Those with big Nvidia (or to a different degree AMD) graphics cards in their 32core desktops will agree - watching a batch go with large parts of the system underutilized is not efficient.
All that said, I’ve enjoyed this discussion and the runs to find out what’s best on my system. I’ll stick to 2 for now, and when PL7 comes out, I’ll redo these tests to see what’s the right batch number for this computer.
2 Likes
My core i9 has 14 cores, and the cpu usage isn’t at a 100% at all during a big batch export. It seems it spikes a few times. Most of the (deepprime) work is done on the gpu.
But I noticed that increasing max processed images will not really benefit much in time. The overal time per image seems to go down way before i hit the max of 10.
I think the gpu is working the most , and the cpu is used to feed and download from the gpu. Gpu utilisation has been a tricky thing to monitor since forever.
On my system, it seems that trying to do much more images at the same time only makes the gpu (or something) wait for data, and the end result is a slower time-per-image.
I haven’t tried dialing in the quickest amount to be honest. I get under 8 seconds per image most of the time with the max concurrent set to the default 2, and this is quick enough for me, and i can still do something else on the system ![]() .
.
Anyway… what I’m saying is that increasing the max past 10 might not actually increase your overal average time-per-image.
I don’t know the mac efficiency of DxO to be honest.
But if all the work is done by either gpu or neural cores , having more cpu cores isn’t really going to help.
Yeah basically I think this feature request should be withdrawn (or not voted on). 10 images at a time is already overkill, a waste of memory, and in some cases marginally to substantially slower…
Unless someone comes here with a 32 core machine loaded with 6 GPUs and reports that Photolab will spread the work across all of those GPUs I think this case is closed.
Incidentally the processing engine is already multithreaded as I have 8 cores and 16 hyperthread virtual CPUs and processing two at once with no deepprime where all processing uses the CPU exclusively pegs my CLU utilization at the max which means all cores are going while processing only two images.
Let’s not forget that other things might need or want to be run while DPL crunches away some export. If processing units were loaded to 100% each, the system would be quite unresponsive to any clicks or mouse movement. DPL should under no circumstances monopolize computing resources imo.
User can easily control how many core are allowed to any software (at least on windows). I generally let 2 cores free when doing extensive computations wich push all cpu core to 100% (not photolab) and still need my workstation to be “alive”.
So this shouldn’t be too much difficult for developpers to do that or even give an option in preferences for example.
But I agree that any IA computation should be done with specific circuits (graphic cards/neural cores) and not cpu cores. This does not make sense IMO.
1 Like
@MikeR - the underlying point is that the request is really about optimizing the batch processing better. Plus, I’m not looking at timing with ‘no’ deep prime, as I do a lot of high ISO shooting (indoor theater and the like) and I need the DeepPrime and the XD variants to work properly. Those two are heavily using the neural network engines, but there may be a way to optimize by ‘every tenth’ using all GPU, as the GPU cores are not fully loaded.
@platypus - for some users (many of whom never even open the settings in the first place), that might be fine. But, different systems have different architectures and therefore different strengths/weaknesses and as such, IMHO, default options should be different based on that. That said, some of us will continue processing when running a batch, some of us will go grab a coffee or dinner. In other words, not EVERYONE will need a fully responsive system while processing. Some times, I want to know that I’m getting my money’s worth with the system being fully loaded.
@JoPoV If you look at the screen capture I did (above) of the cpu loading and the GPU loading, you will see that the CPU is used periodically, and the GPU in this system is being used lightly. My ask here is to have them consider better load balancing when batching photos, as I consider this to be unoptimal. That said, my system is entirely usable while doing the batch as the normal PL processing (rendering previews, etc) seems unaffected by the batch in the background. So, it’s very much alive. My laptop (MacBook Pro intel based with a GPU) was crushed by batch processing, so that system was more or less unusable while running the batch.
It would be nice to be able to tune the processing to be able to reach a balance (between batch processing loading and PL rendering) that’s specific to this system. That’s the ask.