@Brunok1 As has been pointed out in the earlier posts, the search is of the database, the whole database and nothing but the database!
As @George and @platypus have indicated you need a copy of the database that relates to one drive but then that drive needs to be attached at the time of the search.
Having a mixed estate of images from one drive or another or another plays havoc with the counts returned by DxPL for any search!
The entries in the database get there when you discover a directory , regardless of whether you edit the images or not (they will be “edited” automatically using the ‘Preferences’/‘Correction Settings’ the first time they are “discovered” directly by the user or via indexing).
DxPL is an editor not a viewer, so every image “viewed” in DxPL is automatically added to the database. If you view images in the same directories on Drive 1, Drive 2 and NAS or ‘Index’ the images on any of those drives they will all be added to the database.
If those directories are actually copies of one another then you could wind up with as many as three entries in the database for the “same” image.
All searches are made via the database and if any drive is absent you will get the nasty surprise that you showed in your post.
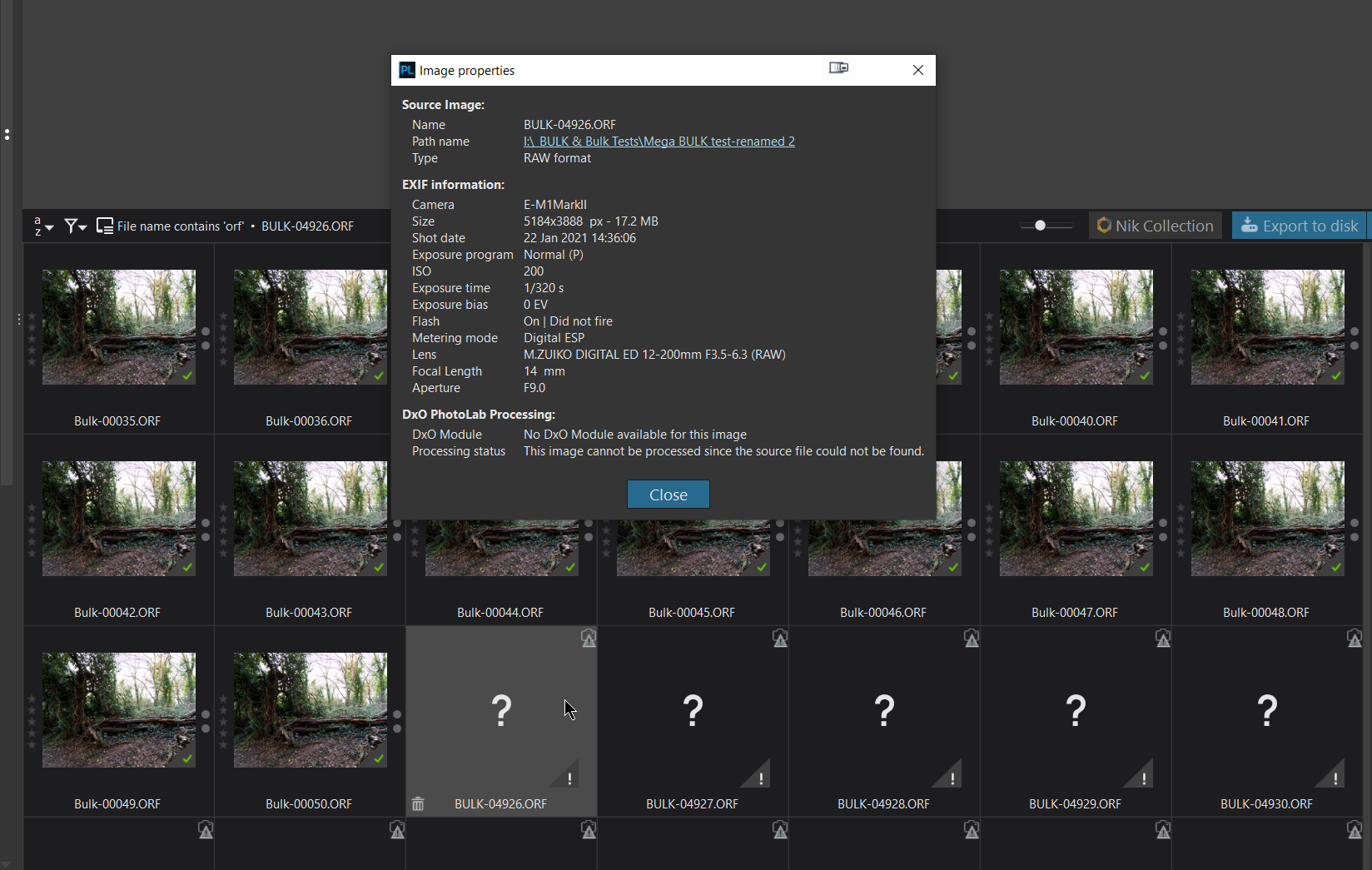
So in my case I had done a bulk load of images as part of a timing test and the drive was switched of when I did a ‘Search’ and I got the following when I did a search on “orf”, the extension for images from my EM1 MKii, taken some years ago and used to create a large batch.
Please note that I had loaded a smaller batch from my NVME drive of the same but differently identified images and they are still on the machine. If those images had been named identically I would have had thumbnails for those on "N:" mingled with those with the “surprise” thumbnails for those on "I:"!
‘Sorting’ provides these options, not particularly useful to “cluster” the images in a useful way, but adding the ‘Drive’ as an options available would be useful.
and filtering provides these options which don’t offer such options as ‘Present’ or ‘Absent’ or ‘Drive Letter’ or …
As I suspect you have realised already there is not any way that I can see that you don’t retrieve what is not present in a ‘Search’ and cannot ‘Sort’ or ‘Filter’ out those that are present from those that are not present or vice versa.
I tried searching on "N:" the NAS and "I:" the (currently) missing drives but neither search turned up anything
Throwing the database away simply means that no searches within DxPL are available and ‘Projects’ (‘Projects’ and ‘Advanced history’ on the Mac) will be lost and the proposal is then to only edit on one drive and to index that drive.
Editing on more that one drive would be a potential nightmare anyway but the only way to view what edit you actually have on any drive (copy) for an image is to open the image in DxPL and it is immediately found in or added to the database!