Does Photolab 6 will have the AI generative fill in the future (like photoshop) ?
Thx
I doubt you’ll get an answer to any question on future product features, but my gut feel is that it’s not something that we’ll see in the foreseeable future.
I asked for something simpler to fill in missing edges, like Content Aware Fill or something similar. Generative Fill AI, I don’t think is likely to come from a company like DXO for variety of reasons.
a) It requires a pretty substantial infrastructure or downright stealing or licensing of cloud based service. Other than offering some optics modules, DXO is not a cloud based service, and its therefore also not a subscription service. Adobe is.
b) Adobe has a huge cloud business outside of creative cloud as well as creative cloud. it has also bought up many stock photography websites to train its AI. It has been doing this for many years and has a budget that makes DXO look like a street vendor vs a budget of a small country.
c) Open AI, Stable Diffusion etc. has basically stolen everyone work online and trained their models. Its the equivalent of stealing everyone’s bikes in the town and than opening a bike rental shop. Not cool.
d) DXO could license a service from Adobe maybe. Adobe did mention they will offer Firefly to enterprise, but it would than mean someone has to pay for it. DXO or users. Either way, it would become cloud service, meaning subscription service. Not cool.
e) The only real benefit you woudl get is filling out the edges or removal brush, but again, problem one, cloud service, and problem two subscription and problem three Generative Fill is still 1024x1024 px, or about 1 MP is dimensions. Leaving a lot of details on the table. If you worked with Photoshop you could what that means for any higher resolution images. A big misssmatch between generative fill and actual original resolution of the image.
f) Possibly something like Remove brush that is really good in Photoshop, could be replicated in DXO at some point. But to be honest., it just makes more sense to use Photoshop for most of such work anyway. Pick the best tool for the job you need.
1 Like
v6 will NOT … for a simple reason - there will be v7 and AI degenerative fill is a MAJOR feature
if this ever comes out, it will be in a new PL “X”, not an already released version.
somehow we all know who ![]()
Kid, do you really want to make this political? No, you don’t. So I suggest you find some other place to troll, since its the only thing you know how to do… noname.
5 Likes
There are feature requests for a smart fill. One can search the forum and vote for it. Won’t be added to PL6, though.
2 Likes
Hmmm, not sure about that one. First off, I still have full access to all my photos online (doesn’t apply in your stolen bike scenario), and second, they’ve added a lot of value from sampling images online. I haven’t lost anything and I have access to something I could never do myself.
That is how software/music/movie pirates justify their activities.
Except they’re stealing content from people who charge for their products (i.e., one pirated CD means one less CD sold legitimately and so a loss of income to the content creator). Does that apply in this case? I don’t care if a company uses my publicly posted photos for its AI training … I lose nothing, and it leads to a product I might be interested in. Why would you care? What exactly are you losing?
Obviously, you lack understanding how inflation works. Or monopolies. Or copyright. And why it matters. Allow me to explain it to you.
If you don’t understand the bike reference, maybe you will understand that inflation reference, instead.
Inflation, as in monetary inflation is an expansion of money supply. When central banks issue credit these days, they don’t even use money (gold, silver) or credit linked to money (gold, silver), they issue credit linked to nothing other than confidence in government authority, often enforced by law, threat of prison, etc.
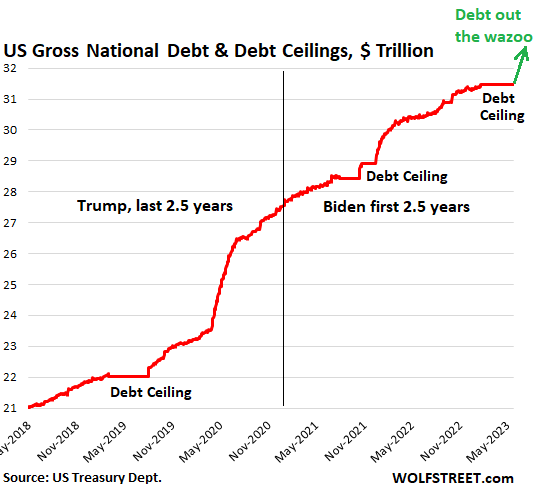
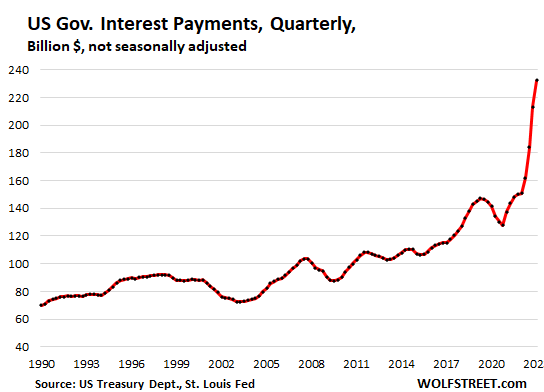
The create, fiat US dollars. Which means that they can mouse click into existence trillions of US dollars at any point, and they often do. Hence US government in nominally $32 trillion in debt, and will soon be paying $1 trillion in annual interests. These numbers are so enormous that one cannot even fathom it. It’s just statistics.
Fiat currency: A fiat currency is a type of currency that is not backed by a physical commodity. Instead, its value is derived from the trust and confidence of the people using it, as well as the authority of the government or central bank that issues it. Fiat currencies are declared legal tender by the government and are accepted for all public and private debts. Most modern currencies, such as the US dollar, the euro, and the Japanese yen, are fiat currencies.
When they global cabal or unelected beurocrats at WHO changed the definition of pandemic so they can declare it worldwide, all the governments, locked people down, restricted movement, and pass down stimulus checks of that fake fiat credit. And then encourage people to bet in the casino government and their cronies own. Stock, crypo, release estate and financial markets. Stocks in particular. In about two years FED (Federal Reserve Bank) flooded the financial market with almost 9 trillion US dollars.
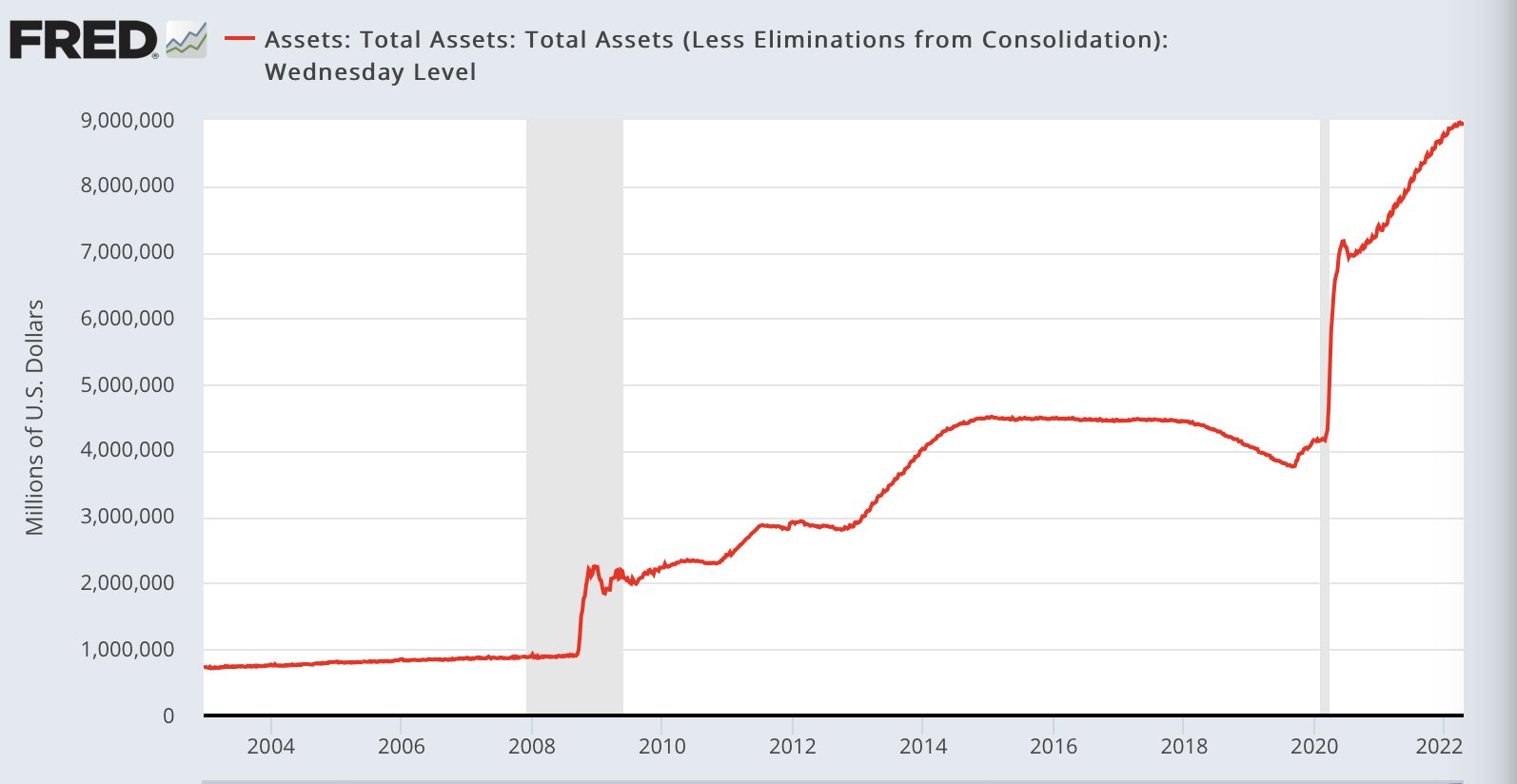
On January 1, 2020, bitcoin was trading at $7,160. The Dow Jones was also trading at 28,634 on January 3, 2020, before crashing to 19,173 on March 20, 2020, after the coronavirus pandemic broke out in the United States. States and the Federal governments immediately shut down the economy and millions of people lost their jobs.
As part of its effort to stimulate the economy, the U.S. government issued stimulus checks to millions of employed Americans. Where did the money come from? The government had to borrow by selling its debt in the form of U.S. Treasury bonds and other types of securities. The after the bonds are sold, the Federal Reserve gets to work and starts printing money.
What happened is that they stuck the extra credit into stock markets, crypo etc. Ballooning the price of these otherwise worthless financial assets. Because the price of stocks went up, not because companies actually did something, but because there was more FED credit in the stock market (wall street speculation bubble or casino), and as a result of more dollars chasing same stocks, the price went up to compensate. Than the gamblers or rather owners of the casino got really greedy so they forced shut down of small business, kept the big chains open, like Amazon, Wallmart etc. And gave people stimulus checks, encouraging it to spend it on gambling in wall street casino. Stock market. Crypto etc. But house always wins, and so billionaires became more rich and everyone else… oh well. They didn’t own a casino.
This is called by some “wealth effect”, because its easier to make a billion if you are millionaire than it is to make a million if you are poor guy off the street.
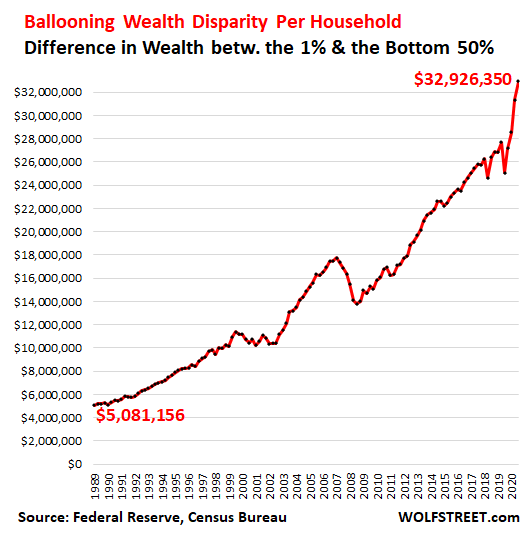
Than the new billionaires could buy stuff that normally would be bough by everyone else. Except now they cannot afford it anymore, no one but the richest. And the problem is that purchasing power of everyone’s dollar is going down, because of inflation, or expanding monetary supply. Eventually, all that extra credit of dollars didn’t stay in stock market, it spilled over into other areas and that is why today, you have to pay so much more for gas, energy bill, food etc. And its going to get a lot worse.
But money printing is not new. The Federal Reserve has been printing money to pay for about $29 trillion in U.S. debt. However, what’s new is that the 40% of US dollars in existence were printed in the last 12 months alone (2020-2021)
“80% of all US dollars in existence were printed in 22 months (from $4 trillion in January 2020 to $20 trillion in October 2021)”
“The Federal Reserve’s balance sheet ballooned following its announcement to carry out quantitative easing to increase the liquidity of U.S. banks. The balance sheet of the Federal Reserve reached around 8.27 trillion U.S. dollars as of July 19, 2023. The most drastic increase in the observed period took place in the first half of 2020. This measure was taken to increase the money supply and stimulate economic growth in the wake of the damage caused by the COVID-19 pandemic. The Federal Reserve was not the only institution that implemented an expansionary monetary policy in response to the pandemic. For instance, also the European Central Bank expanded its money supply in March 2020, and kept doing so over the following months.”
You don’t have control over the quantity in circulation and by extension the value measured as purchasing power of the dollar. To not care what FED is doing, thinking your dollars are safe in your pocket or under your mattress, shows lack of understanding how inflation and currency work. I imagine, based on your previous comments you have the same lack of basic understanding how inflation of images work and how counterfeiting works.
If you or I were to start counterfeiting currency by printing it at home and starting exchanging it for goods and services, the government would put us in jail, not because it objects to the method, but because it is competition to the same thing they are doing. Now, if I printed on my home printer 100$ US dollar bill and gave it to you for the exchange of some service. Would you take it? And if not, why not? It’s the same as what the government does? So why do you accept counterfeit from governments and central banks, but not from me?
Mostly likely for two reasons. a) You don’t understand the underlying process or what money is. b) government has a monopoly on violence so it essentially forces people to use their fake fiat. c) most people are like you, so it can keep the Ponzi scheme going.
When you keep US dollars in a bank, or you keep them as physical bills under matrices, central banks and government is stealing the purchasing power of those dollars, effectively devaluing it, because they control how much of it is in circulation. If more dollar bills are chasing the same amount of goods and services than you need more dollar bills to compensate, often seen as the price of goods and services going up. Which really should be seen as the purchasing power of currency going down.
Inflation is a silent tax. Except, virtually everyone is taxed by it. Even those that not only hold US dollars around the world and are not American Citizens, but also all the other currencies pegged to the US dollar, which is world reserve currency… still. This makes FED who creates US dollars out of thin air, effectively the most powerful institution in the world, because it is the de facto World Bank.
FED was introduced in 1913, and since then the purchasing power of the US dollar fell by about 98%.

To encourage everyone to spend this bank credit created out of thin air. Central banks lowered interest rates to negative territory. Impossibility. But they did it anyway. Borrowers were getting paid to borrow. Why? Because when you have the power to print money at any rate you want, then you want others to borrow it and spend it in your casino so you profit from it. That is what basically happened.
So when you think that what FED does is not something you worry, about. You should? Because it affects us all.
When Open AI or Stable Difussion or similar models “print”, scraped images and text out of everyone else. That is similar to when FED creates trillions of US dollars and puts the nominal interest into negative field.
When a loaf of bread is priced in $trillions of dollars, call me and we can revisit this discussion. Hopefully by then you will realize the nature of the problem.
Inflation from 1913 to 2023 In 1913, gold was $20 per ounce, in 2023 it is $2000 per ounce, or a 9900% increase. In 1913, a barrel of crude oil was $0.95, in 2023 it is $80.6, or a 8384% increase. Ht u/nik7770
Perhaps no subject is as important to mankind as the nature of money, which has been so neglected and misunderstood in both the popular and professional mind, to the great detriment of the intelligent and just operations of societies. If it wasn’t for politicians and central bankers finding it impossible to resist either using currency as a tool for economic management or simply as a source of funding government spending, the distinction between money, which evolved into gold and silver through market forces, and currency, always a creature of the state, it might not matter.
But the British economist mathematician, John Maynard Keynes, quoting Lenin said: “There is no subtler, no surer means of overturning the existing basis of society than to debauch the currency. The process engages all the hidden forces of economic law on the side of destruction and does it in a manner which not one man in a million is able to diagnose.”
Modern monetary economists define hyperinflation as any inflation rate above 50 percent per year. In the 1920s, Germany had inflation rates in the thousands of percent.
Far too many German marks were being created under the privately controlled Reichsbank. Exactly how, will be discussed shortly. These excessive issues drove down the value of the mark:
By July 1922, the German mark fell to 300 marks for $1; in November it was at 9,000 to $1; by January 1923 it was at 49,000 to $1; by July 1923, it was at 1,100,000 to $1. It reached 2.5 trillion marks to $1 in mid-November 1923, varying from city to city.

The Vampire Economy is a book by Günter Reimann. It is a study of the actual workings of business under national socialism. Written in 1939, Reimann discusses the effects of heavy regulation, inflation, price controls, trade interference, national economic planning, and attacks on private property, and what consequences they had for human rights and economic development.
IN NAZI GERMANY there is no field of business activity in which the State does not interfere. In detailed form it prescribes how the businessman may use capital which is still presumably his private property. And because of this, the German businessman has become a fatalist; he does not believe that the new rules will work out well, yet he knows that he cannot alter the course of events.
He has been made the tool of a gigantic machine which he cannot direct. He looks at the rest of the capitalist world, hoping for help in winning back from the State his lost rights and freedom. But wherever he turns there are trends and changes of a similar, though milder, character, indicating that the totalitarian regime in Germany cannot be attributed to the madness of one man or to the self-interest of one ruling party; that it represents in caricature some of the fundamental phenomena in modern capitalism, which lead to more and more State interference and consequent usurpation of the businessman’s rights and privileges.
“Under Bolshevism all your cows will be taken away from you because you are a kulak (wealthy independent farmers in the Russian Empire, designated as the class enemy in the Soviet Union). Under National Socialism you are allowed to keep the cows; but the State takes all the milk, and you have the expense and labor of feeding them.”. - Günter Reimann, “The Vampire Economy”
So you see, vampire economy first ignored copyright law and allowed companies behind stable diffusion model and Open AI to scarp everyone’s text and images. Than they claimed, AI is dangerous, needs to be regulated. Meaning we got the advantage now, and now we have to make sure no one else is in competition with us. So the people who control FED and dollars, and by extension much of the world as long as people use dollars, has meeting in Portugal, Lisbon. The infamous Bilderberg Meeting
annual private conference of 120 to 150 people of the European and North American political elite, experts from industry, finance, academia, and the media.
Now guess who was invited for the first time to attend the meeting this year? One Sam Altman. the CEO of Open AI.
Secretive Bilderberg Gathering Of Global Elites Kicks Off: See Who’s Attending & What They’re Discussing
Thursday, May 18, 2023 - 08:20 PM
Authored by Tom Ozimek via The Epoch Times,
The 69th Bilderberg Meeting, a secretive conclave of global power brokers, has kicked off in Lisbon, Portugal, with issues on the agenda including transnational threats, artificial intelligence, and America’s leadership in world affairs.
This year’s meeting, the latest in a series that began in 1954, continues to blur the lines between open diplomacy and clandestine elitism as political leaders brush shoulders with industry bigwigs, media barons, and finance tycoons.
“It’s a really high-octane list, leaning heavily into the Russia/Ukraine conflict and the future of NATO,” journalist Charlie Skelton, who’s in Lisbon to cover this year’s event, told The Epoch Times in an emailed statement.
As usual, the details of their discussions remain obscured by the “Chatham House Rule,” a protocol that gives participants the discretion to use the information gleaned from the talks but forbids the identification of speakers or participants, ensuring anonymity.
“Thanks to the private nature of the Meeting, the participants take part as individuals rather than in any official capacity, and hence are not bound by the conventions of their office or by pre-agreed positions,” a Bilderberg Meetings press release reads.
Among the major topics slated for discussion are artificial intelligence, the banking system, energy transition, and industrial policy and trade.
Other high-priority issues include the geopolitical landscapes of Europe, China, India, Russia, and Ukraine, along with NATO and America’s global leadership.
The topic of U.S. leadership, which last appeared on the Bilderberg agenda in 2018, comes as China and Russia have ramped up their efforts to reduce reliance on the U.S. dollar as the world’s pre-eminent reserve currency.
The agenda outlined by the group is as follows:
- AI
- Banking System
- China
- Energy Transition
- Europe
- Fiscal Challenges
- India
- Industrial Policy and Trade
- NATO
- Russia
- Transnational Threats
- Ukraine
- US Leadership
Also attending is Sam Altman, CEO of OpenAI, the creator of the artificial intelligence chatbot ChatGPT that has grabbed headlines for its potential to replace humans in jobs. Other prominent tech figures include Satya Nadella, CEO of Microsoft, Alex Karp, CEO of Palantir Technologies, and former Google CEO Eric Schmidt.
Albert Bourla, CEO of Pfizer, is also on the list of participants, as is Thiel Capital founder Peter Thiel, and John Waldron, president of Goldman Sachs.
And after that there is talk of regulating AI, and forcing potential competition to get goverment approved license before they can steal as well. No doubt, only if you are aligned ideologically and political with the people at the Bilderberg meeting.
Meanwhile, anything you post online, text or images, can be stolen by Open AI or other approved models, no copyright there, but if you take Google logo or something, you will be sued to oblivion faster than you can say; “that’s not fair”.
On top of that , there is censorship and social engineering associated with the use and control of these technologies. Open AI is off course very woke and ideologically aligned with certian agendas. Censorship is not the only problem, though. As well as copyright, there is also a problem of inflation. When anyone can create images with a few text prompts can write a blog post. well, much like US dollars, the value of these important cultural elements, cultural currency if you like, will be lost.
We depend on ability to communicate with text and images since earliest civilizations. We depend on ability to be able not just use it for communication but to use it to for trust building, and meaning. You inflate that currency, you will cause havoc the size of which is hard to imagine. And everyone, I do mean everyone will be effected by it.
As for stealing data. Open AI and their large text model is pretty obvious and self explanatory, but its important to note that it does not understand anything and does not speak English or other languages. What it does it is fed large language database of text, created by everyone else online, it than converts words and letters into tokens.
Large Language Models (LLMs) use tokens as the fundamental building blocks for processing and representing text data.3 A token is 4 characters, about 0.7 words on average, and can be made up of different combinations of a-z, A-Z, 0-9, symbols, and other characters including whitespace.
The way that tokenization is different depending on the different models Ada, Babbage, Curie, and Davinci is mainly based on the number of tokens or the vocabulary size that each model uses. Ada has the smallest vocabulary size, with 50,000 tokens, and Davinci has the largest vocabulary size, with 60,000 tokens.
Language models work with tokens and require a tokenizer to convert a text to the sequence of tokens the model can handle. Running a model that large will require a ton of computational resources, so it isn’t ideal to run them on home computers.
These tokens than are analyzed and statistical patterns are created by neural networks which recognize which letter or word, tokenized comes more often before which other word or letter. Hence, it does not understand that word “my” comes before “house” to mean my house. it understands that “my” in token language, statistically is more frequently used than “it”, hence my house is more statistically common than it house. With a lot of computer power, pattern recognition and large data set. that is how it is able to convert tokens into words, and back, and statistically connect them so that when humans read it, it makes sense.
“ChatGPT is a statistical representation of things found on the web, which will increasingly include ITS OWN output (directly and second hand). You post something picked up from it & it will use it to reinforce its own knowledge. Progressively a self-licking lollipop. Enjoy #AI” - Nassim Nicholas Taleb, @nntaleb
Syntax (AI) vs semantics (human).
I asked ChatGPT to tell me the difference between Syntax and semantics
Syntax and semantics are two important concepts in linguistics and computer science.
Syntax refers to the rules that govern the structure of a language. It deals with the way words are arranged to form sentences and how those sentences are structured. Syntax is concerned with the grammatical correctness of a sentence, regardless of its meaning.
Semantics, on the other hand, is concerned with the meaning of words, phrases, and sentences. It deals with the interpretation of language and how words and sentences convey meaning. Semantics is concerned with the meaning of a sentence, regardless of its grammatical correctness.
In summary, syntax is concerned with the structure of language, while semantics is concerned with the meaning of language.
…
When you enter text prompt into ChatGPT it will give you something that might look like believable answer but it has not understanding of what it is, and there is no ethical consideration. Only statistical processing of stolen data set, plus one that is generated from prompts.
And yet many will think they are talking to digital human and will be too lazy to check the accuracy of “answers”. Along with censorship, and copyright, and accuracy issues, there is also inflation of data issues. Leading to profound social engineering experiment that can only end in a disaster.
It erodes critical thinking and ethical standards. While the companies behind it use it of nefarious reasons. they will also charge you for using it, even if they have effectively stolen all the bikes in a town.
In Japan the goverment mentioned they will abandon copyright law in favor of creating large AI database. Essentially abolishing the concept of private property. State ownership and central planing. What could possibly go wrong? And who could possibly be effected by this? Hmmm.
…
As for stable diffusion model for generative AI images. The way Stable Diffusion method works is similar to the Rorschach test is a projective psychological test in which subjects’ perceptions of inkblots are recorded and then analyzed using psychological interpretation, complex algorithms, or both. Some psychologists use this test to examine a person’s personality characteristics and emotional functioning.
Stable Diffusion starts as image of random noise, and than uses its vast database of images and text prompt from the user to gradually morph noise elements into recognizable picture elements.
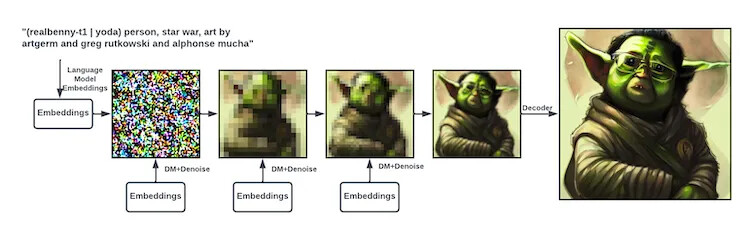
It uses data of images made by others at first and eventually by itself, and text prompts are like basic ChatGPT large language model of recognizing text and associating it with images.
Both text to train the large text model for prompts entered as text and the images to have in the database are scarped all over internet, without knowlage or consent from original creators. This stable diffusion model than was offered online for everyone to use and improve upon, which some companies like Mid-journey did for cash. Hence my Bike rental analogy.
And its easy to find images made by this model and compare them to original images from creators and see they are stolen.
" [N] Getty Images Claims Stable Diffusion Has Stolen 12 Million Copyrighted Images, Demands $150,000 For Each Image
From Article:
Getty Images new lawsuit claims that Stability AI, the company behind Stable Diffusion’s AI image generator, stole 12 million Getty images with their captions, metadata, and copyrights “without permission” to “train its Stable Diffusion algorithm.”
The company has asked the court to order Stability AI to remove violating images from its website and pay $150,000 for each.
However, it would be difficult to prove all the violations. Getty submitted over 7,000 images, metadata, and copyright registration, used by Stable Diffusion."
Now, Getty images was already a stock website and than it was robbed. This is what Adobe did, but they were clever and devious to do it legally, even if its unethical.
Adobe Firefly their generative AI service, has not “stolen” images per se. But Adobe trough various unethical means and monopoly protection from the goverment, acquired, merge and bullied themselves into buying stock photography websites like Fotolia for example and therefore creatively “acquired” licenses for the large image data set, they used to train their Firefly models. Off course people who uploaded their images to fotolia, or used it, didn’t image it would be sold to Adobe, or that their images would be used in this way. Also, when you upload the images to Creative cloud to use their service, which is not free, you are also, training their models for which they will charge others, including yourself later.
Google is working on their AI, which means all the emails via gmail, all the YouTube uploads and Google Photo uploads and probably Android usage data, was used to train it. Microsoft is the same. Did we all consent to that, were we asked? Were we given a choice? No. And yet it will impact so much of our culture and economy. Like Inflation, he who has the printing machine repeats the profits. Everyone else is screwed more or less.
Asking DXO to compete with this, as a small company, is asking DXO to become a kind of company that is not part of their DNA. DeepPrime is one thing, since they anylize images as part of their core business, but generative AI and all that, text prompts etc. Is something else. They could do it, but either by stealing, licensing, or some other method that I’m not familiar , but when you think how small the company is, and how specialized it is, seems like its an investment into something they probably can’t be number one and can’t really justify the cost. Cloud service, subscription etc also a problem. And if they make it offline database. I imagine it would make the app pretty bloated for something very specific. There are options to download stable diffusion database and use it offline, as a condense database of everything collected, but it takes a more powerful hardware to run it locally, and not in cloud, and the size of DXO PhotoLab would probably be in many gigabytes.
Companies like Amazon, Apple, Adobe, Google, Microsoft. OpenAI etc. benefited immensely from stock market schemes and credit printing, and were able to buy political protection for exemption from law and political protection for monopoly power. Once they get advantage like that, they will pretend to be “good samaritan” and lobby for regulation of AI, where they close the door so the competition now has to get approved license to do the same thing. Meanwhile, these companies will continue to play dirty because they can get away with it. And if you are regular user and not a company and you just make some art, or photos they will have no hesitation to steal it form you and charge you or others for AI services.
2 Likes
That wuz a long post. You forgive me for not reading it.
9 Likes
Silly me. I thought this was a site dedicated to the software created and marketed by DxO Labs. When did it morph into a discussion of geo-economics. @sgospodarenko or @StevenL perhaps this contentious thread, which is going downhill very quickly, should be locked.
Mark
9 Likes
Sorry, my eyes caught sight of the term, ‘global cabal’, so I decided not to read the rest. One of us has more time on their hands than the other. All the best…
So, the upshot of all that is that it is impossible and prohibitively unaffordable for the small DxO to produce anything remotely like the cutting edge AI generative fill of the Goliath that is Adobe.
I would settle for being able to clone into the empty corner triangles caused by image rotation. Fixing cloning at the edges (it produces smudges) would be a start.
That would be nice!
Ai generative fill is for pixel editors, not RAW converters.
2 Likes
Many of us long-term users of DxO products are intimately familiar with their software and their year to year upgrades to it. The idea that DxO might be considering the addition of an AI generative fill feature, similar to Adobe’s, any time in the near future, would be laughable. I’m very confident it’s not even on their long-term plans. Using AI in that manner is just not part of their current vision for this software. Something like an improved content aware fill would be much more likely.
Mark
6 Likes
But I observed that the market goes to AI, so should DxO not going the same way?
I have tried these days a big retouch on a photo, it cost me with Adobe Photoshop one hour, using PL and Affinity Photo 4 hours. My decision was clear …,
…apart from DeepPRIME, which seems to have a machine learning background as described here:
https://blog.dxo.com/denoising-technology/