Off course.
George
Off course.
George
@Joanna because every piece of software I use understands that syntax, i.e. a|m|b and if it is good enough for the xml sidecar it is good enough for me!!
While the pipe might work as delimiter, I prefer to use the < and > signs when entering a hierarchical keyword for the first time. This allows me to clearly distinguish top down and bottom up entries.
Examples
@platypus thank you for repeating what I wrote earlier but the | syntax works just fine with my brain and has no special significance on Windows for anything else or so I believe.
DxPL accepts all three syntaxes which is convenient as does Capture One if memory serves me, albeit I got confused when I used Bear<Mammal<Animal!
When it arrives in the sidecar we have
<lr:hierarchicalSubject>
<rdf:Bag>
<rdf:li>a|m|b</rdf:li>
</rdf:Bag>
</lr:hierarchicalSubject>
so what is all the fuss about!
You do it your way and I will do it my way, which just happens to coincide with the entry in the xmp sidecar file.
PS and some software allows both to be defined but doesn’t understand that they are synonyms!
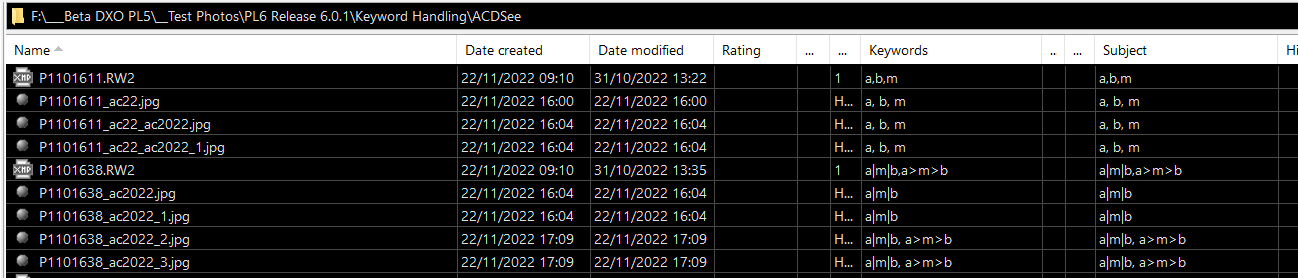
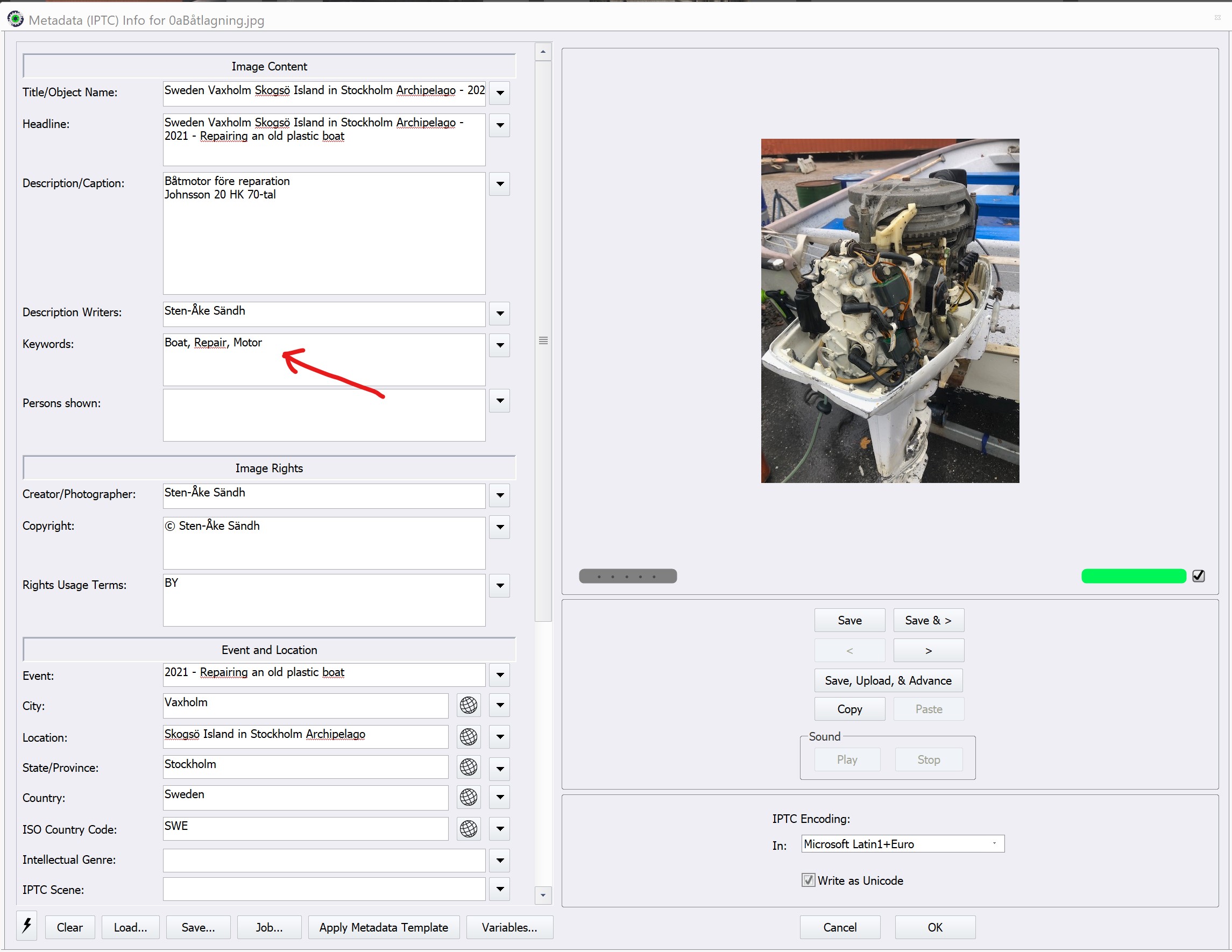
Hmmm. I just tried using PL5.5(b81) to export a RAW file, for which I had written a hierarchical keyword and a standalone keyword to an XMP sidecar, to a JPEG.
Here is the panel showing what was included…
The keywords were all written to the XMP section but nothing to do with IPTC was written.
Not sure what is going one here since I don’t normally use or export IPTC.
My point is that using delimiters in single keywords, which is what you are doing, might “imply” hierarchy but doesn’t get interpreted as such. What you seem to be getting is a list of keywords that happen to contain delimiters.
I understand that, but both < and > are special characters when used in the context of an XML/XMP file and have to be escaped in order to read and write them. It might be fine at the point of entry but, obviously, they then get interpreted, as they are typed, into delimiters that tell PL to write the surrounding words as a hierarchy, in the correct format to the appropriate tags in the metadata. The < and > symbols never get written to the metadata if you are using XMP files - but they can be written to the XMP tags if you write directly to the image file.
Indeed. But they all get translated to single words in the xmp-dc:subject tag and pipe-delimited strings in the lr:hierarchicalSubject tag. As far as I can tell, it is not possible to write a single keyword that contains those delimiters, to a file, using the text entry box.
The fuss is that…
<dc:subject>
<rdf:Bag>
<rdf:li>a</rdf:li>
<rdf:li>m</rdf:li>
<rdf:li>b</rdf:li>
</rdf:Bag>
</dc:subject>
… doesn’t get written into the file, as required by the MWG document.
Possibly because you are using Windows and only using XMP sidecars, you will not notice that the absence of those individual words in the xmp-dc:subject means that the Spotlight search mechanism, that is built in to macOS, cannot find files with those keywords.
One is constrained to only being able to find non-RAW by using PL rather than any other easier means.
The point of entry is the point that matters. Editing sidecar or image files with special editors is not what a DPL user does in most cases. DPL accepts the gt and lt characters (and the pipe?) and does the necessary to get me the hierarchy.
Let’s not mix innards and user interface, the latter being the THING that a user cares about.
If, however, the pipe, lt and gt (and other) characters must be part of a keyword, then ![]()
Agreed. I am just wondering how @BHAYT is getting the pipe characters into metadata when PL, as I have said, parses pipe symbols by removing them?
…have no idea (and interest). Must be a Win-thing ![]()
@Joanna while there might be such a risk, they are all interpreted correctly where the software “understands” hierarchies. For the rest it is just a string and will be passed on as such until such an “hierarchical” keyword aware program is encountered. This is not a function of the string format this is a function of the program’s awareness (or otherwise).
Why I am allowed to do this on Windows I don’t know except that Windows has no special use for the “|” symbol!
However, things are not entirely satisfactory in DxPL land!? I entered “a|m|b” as a keyword but PL6 created the following, as interpreted by PIE (and two wrongs can make a complete …)
When I then attempted to add another string “a>m>b” it was rejected with
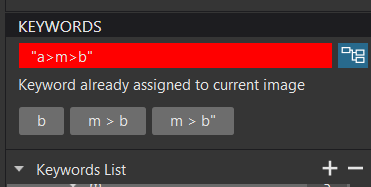
when I deleted “a>m>b” (entered as “a|m|b”) I could enter the new key.
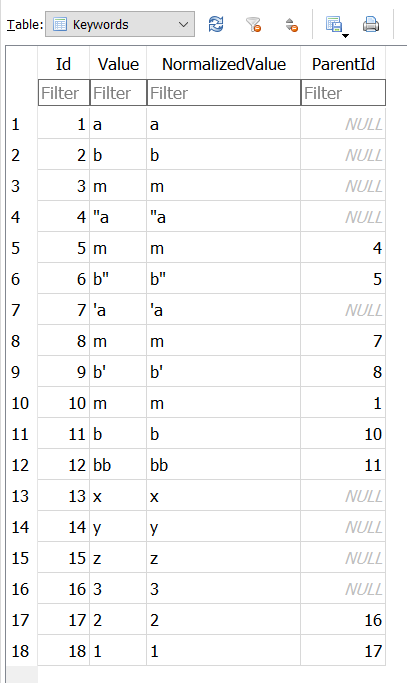
It appears that PL6 is doing a partial parsing of the string rather than taking it for what it is. i.e. a single keyword string!
This is the sidecar and it is a mess!
Although this sort of plays into your argument @Joanna in truth this is some suspect code in PL6! It is not doing anything consistently, as b" as a simple keyword shows!
This is what ‘Keywords’ looks like in the database (I had also tried ‘a>m>b’)
When DxPL spots one of its delimiters(| or > or <) it starts “chopping up” the “hierarchical” keyword. The presence of the " should “disarm” the parsing but it doesn’t and the result is utter …
@Joanna given you seem to have found fault with both ways of entering a keyword I presume that your preferred (on the Mac possibly the only) way is a>m>b or b<m<a?
There are apparently other more important differences too. Since I have been working 7 years in the Cultural Heritage environment in my country I have “been forced” or it was expected of me participate in many different meetings about how to handle metadata and so called standardized controlled vocabularies. There are a few of both those and not controlled ones to choose between and with that said - they did. The National Heritage Board of Sweden developed a pilot project - a web site called “Kringla” and the project was called K-Samsök which means freely translated “Cultural Joint Search”. I left this world six years ago and at that time in typical swedish manner I had hard to see any nationwide standardisation when it came to the cultural heritage sector of society at all. In Norway they had come much further but in Sweden we have a deep culture of seaking concensus in just about everything and that is a really good recipe to achive absolutely nothing.
Before these seven years I was developing business systems for the biggest distributor in the Nordic countries and our vendors were all the big and important IT-companies at that time. My closest work buddie at that time was our representative (listening) in a very big bransch integration program called “Rosetta Net” (named after the Rosetta Stone in Egypt that helped the scientists to solve the riddle of the hieroglyphs). This ad hoc organisation was formed to standardize a joint manner of XMP-communication between the vendors and their distributors. The idea was to develop a standard for XML-invoices, -orders and -order confirmations and the processes that was going to be used. When the standard was beginning to be finished Microsoft made a package with a Rosetta Net Accelerator that was just to be installed at all participants Biztalk Servers. And when we started to set up this server IBM came back and informed us that they had added a few things that made the whole idea with that Accelerator not so standardized.
I read a few things about keywords and where and where not to put them here:
Using the IPTC Subject Scene and Genre codes with your Controlled Vocabulary Keyword Catalog
Quote:
Question: When is a keyword, not a keyword?
Answer (shortened version): When it’s a term from a formally structured controlled vocabulary designed for a specific use with it’s own designated field for storage.
Answer (Longer version): In terms of the IPTC Core, there are three formally structured controlled vocabularies referred to as the IPTC Subject, Scene and Genre Codes. These are sets of designated terms for populating the IPTC Subject, Genre, and Scene fields, respectively. All versions of the current Controlled Vocabulary Keyword Catalog (CVKC) contain these three sets of terms within the hierarchical catalog, however they should not be applied to the Keyword field. These are designed to be placed into the specific field for which they are named, but are included in the CVKC as this is the easiest way to store them for use.
Please Note that the Subject and Scene fields are to only be populated with the controlled vocabularies (available from http://www.newscodes.org/) that are supplied by the International Press Telecommunications Council or IPTC (these have, for your convenience been converted from the XML code to a for that works with your applications keyword catalog). These same controlled vocabularies are not intended to be used in a general field such as the IPTC Keywords field."
(end of quote)
On Subject and Keyword-fields
IPTC Subject Code [SubjectCode]
This field can be used to specify and categorize the content of a photograph by using one or more subjects as listed in the IPTC “Subject NewsCode” taxonomy (available from http://www.newscodes.org/). Each subject is represented as an 8 digit numerical string in an unordered list. Only subjects from a controlled vocabulary should be used in this field, free-choice text should be entered into the Keyword field.
Why not litter The Subject-field ? - The Semantic Wb and Dublin Core
One of the reasons is that the “Subject”-element is both a part of Dublin Core that not just happen to be part of the worlds old metadata for the libraries but it is also one of the really core metadataelements used in the so called semantic web and the RDF-standard it builds on.
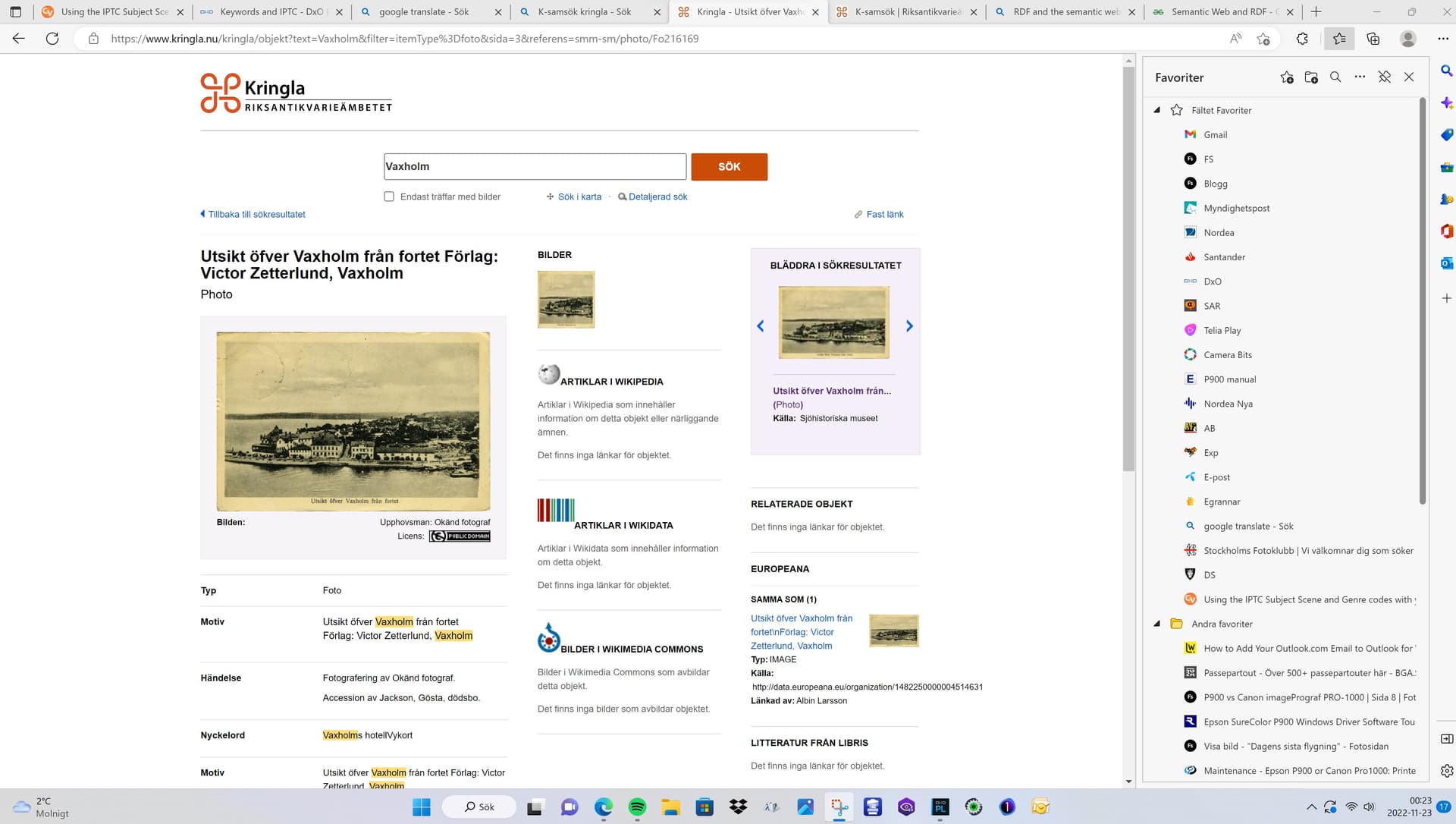
With just a few of these basic elements of RDF which “Subject” is a vital part of, a search on a web like Kringla will automatically be able to look up and display related data from other sites it has communication with.
On the second image below, you can see some examples of this. At least that is the idea. Kringla aggregates image data from the Swedish C H sector (6 miljon images now i think) and Kringla also propagates that info to “Europeana” that is a “Kringla” for all of Europe.
Kringla below is a model for the swedish cultural heritage sector sponsored by The National Heritage Board of Sweden
Here in the image below you can see the Europeana -link and among the others it even looks in WIKI-pedia appearing after search after “Vaxholm” which is my little home town out in the Baltic Islands
But, as @platypus mentions, IPTC is not really the ideal place for keywords and PL6 doesn’t write to the iptc:keywords tag. IPTC also doesn’t contain any means of noting hierarchical context
I’m sorry but this is not true. They are only stored in xmp-dc:subjectand lr:hierarchicalSubject
Wow! I thought they used to be in IPTC as well but, upon checking, you are absolutely right. So kind of DxO to let us know ![]()
Technically I have verified that the metadata even from Photo Mechanic uses xmp-dc:subjectand lr:hierarchicalSubject
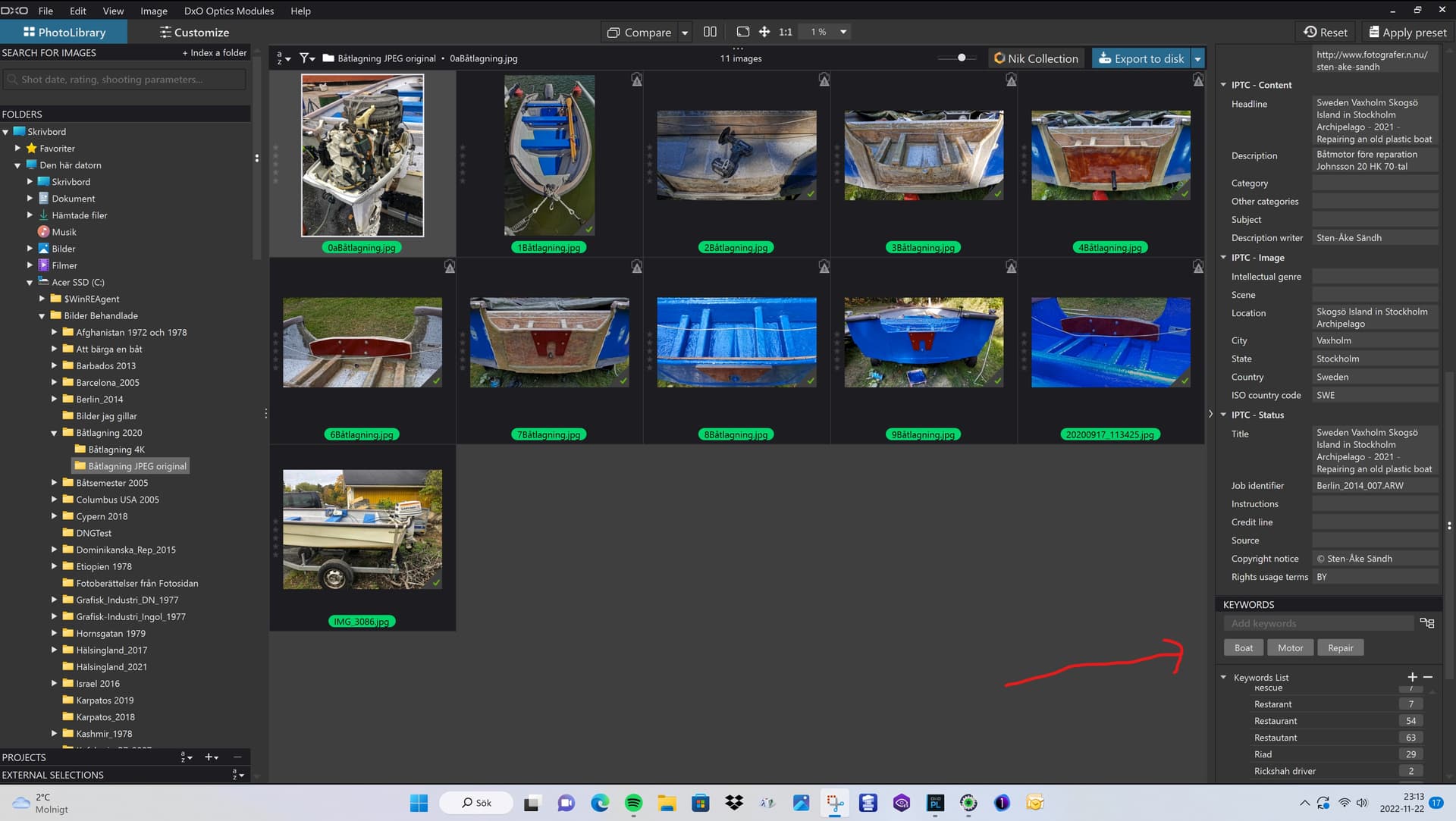
BUT that doesn´t mean that we can neglect what´s happening inside both Photolab and Photo Mechanic. I´ll show you:
Photo Mechanic has never been fully rewritten to accommodate the fact that the industry generally has moved to XMP från IPTC I think - on the paper. The data maintenance result is an XMP compliant XMP-file but the applications entire inside life is IPTC.
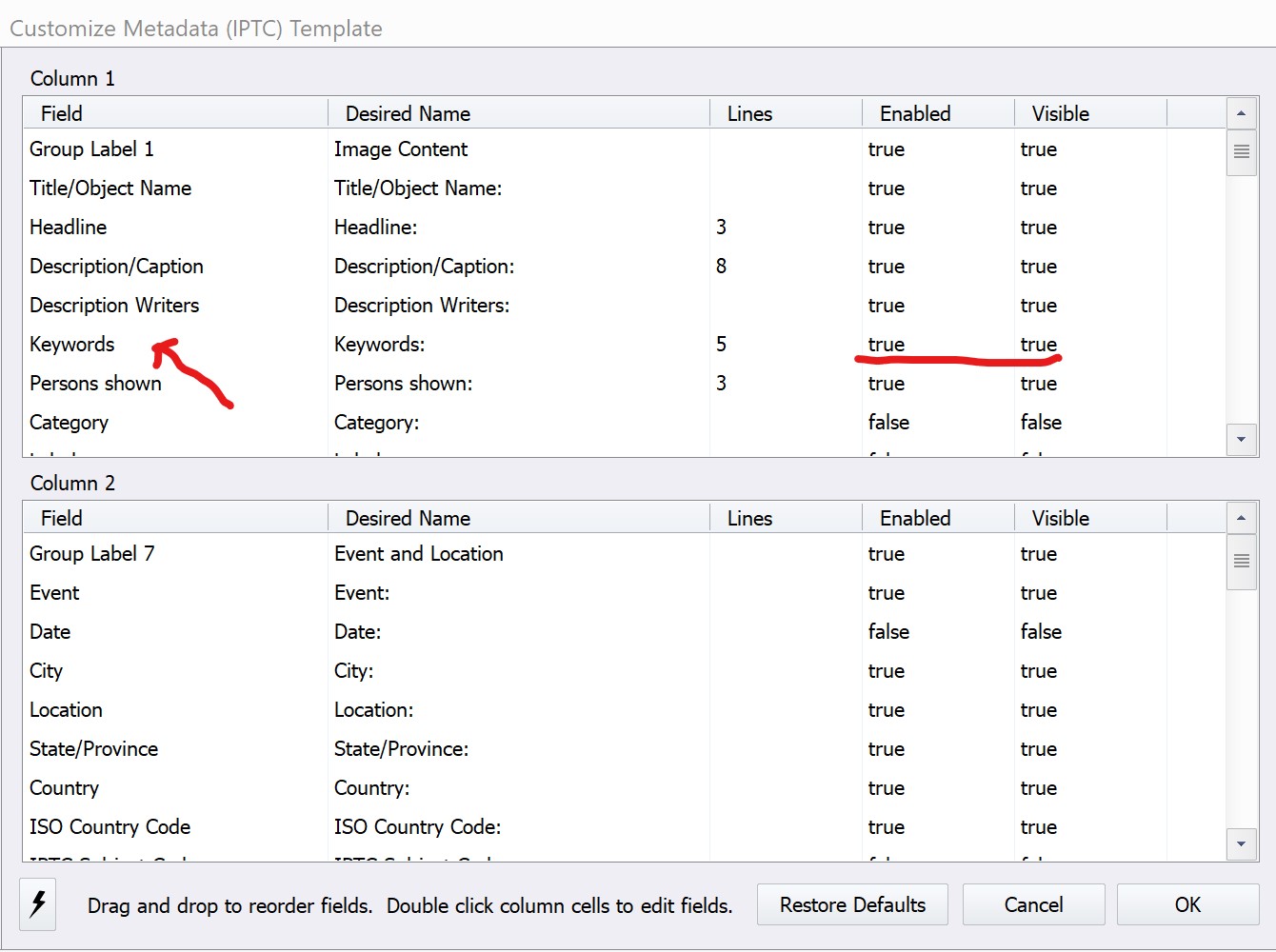
When defining the forms in Photo Mechanic, like the Metadata Info Form and the Metadata Template Form, we don’t use any XMP-schema elements for “Keywords”, that is instead something we pick from PMPlus´s IPTC-schema. We use the old IPTC-element “Keywords”. So, when we update this field, the data is stored in that element internally.
Then we have the option to transfer that data to the XMP-file. We even have the option to write the metadata into the RAW-file if we want. I have chosen to write the metadata even to XMP and when I do so and I have turned on “synchronization” in Photolab 6 the updated PM XMP-data is immediately updated in Photolab if it is open. Is it closed; the updates will be imported automatically the next time I open the folder the file happens to be stored in. It works fantastically well.
When data is imported automatically to Photolab it is also updating both the database and the keyword list with new keywords from the images XMP-files. The keyword list in the IPTC-interface of PL even gets the numbers every keyword is used in the data updated and the IPTC-interface. In Photolab all the IPTC-fields gets updated too, so it displays the IPTC-data exactly as it was updated in the IPTC-fields in PM Plus after updating there. The IPTC-data may be stored in the IPTC Namepaces elements in XMP too but it still somewhere also gets parsed and stored (at least temporary) in Photolabs IPTC elements in Photolabs metadata interface.
This is nothing strange really because many of the metadata editors that was built on IPTC has never fully been written for XMP. We can pretend the heritage of IPTC is gone, but it isn´t.
The Metadata Template is designed by activating the IPTC-elements I want to use in the template. This is done in the References of Photo Mechanic.
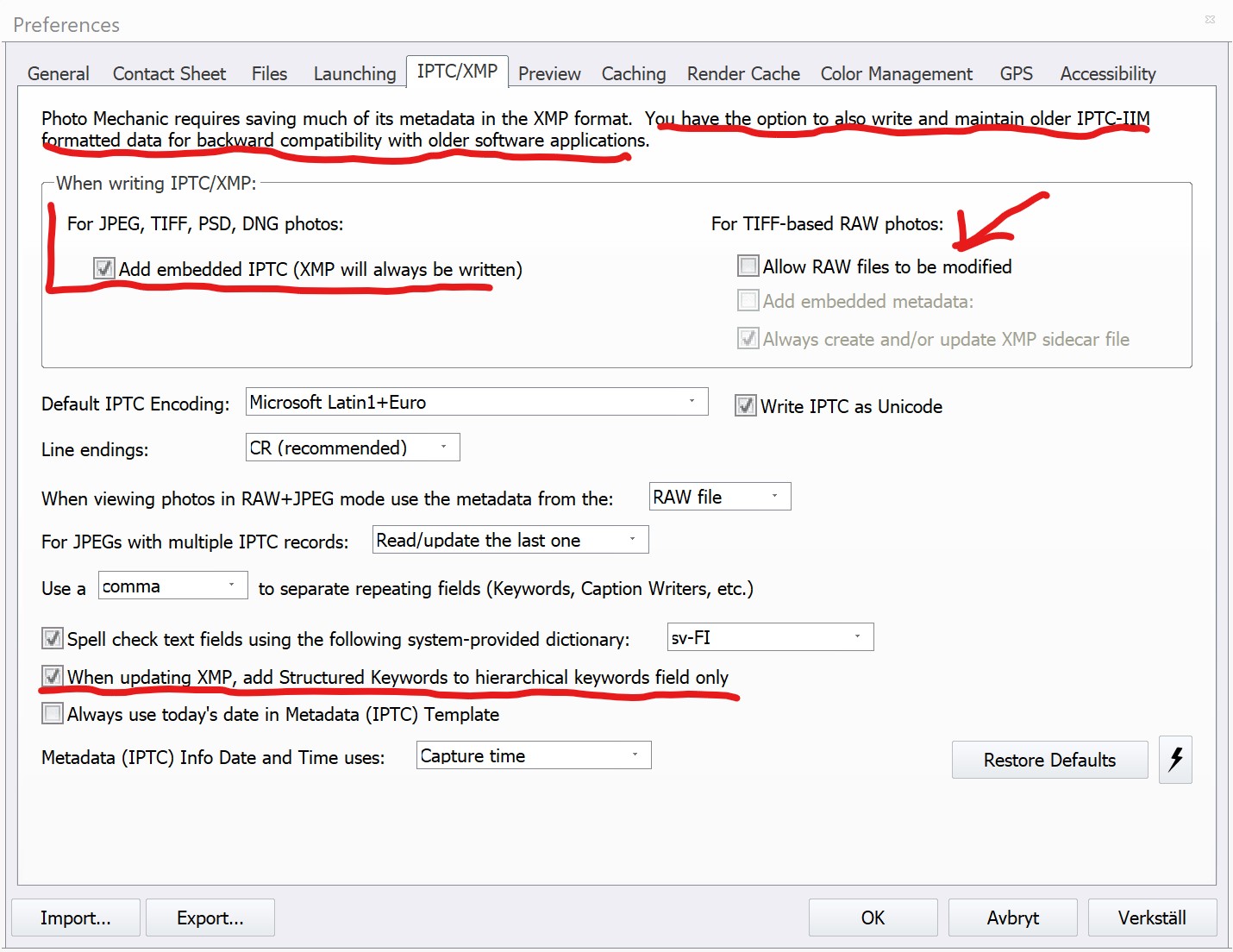
In the references we also specify how to handle the XMP-data both in the RAW and in JPEG, TIFF and DNG
The highly efficient Metadata Template used to batch update the IPTC-data
The Info Maintenance form is used to update the more specific data we want to complement the Template metadata with. It´s almost a mirror of the template form.
Even Photolab has almost the same element set as the ones I have activated in PM Plus and they get updated immediately when updating the same alements in PM Plus and that data gets displayed as IPTC even in Photolab. All the XMP stuff is hidden from the Photolab-interface - or it´s really just an XMP stored outside the application. One can ask oneself why? Well, this industry is a very conservative one and I guess that´s the real answer. Apparently, the death of IPTC seems a little bit exaggerated - even in Photolab.
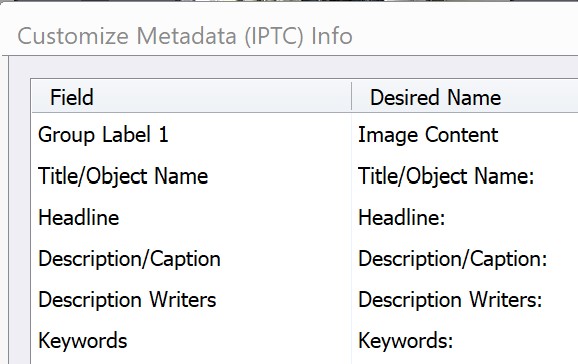
What is really written in Photo Mechanic Plus?
“Customize Metadata IPTC Info”
What is written in the metadata headers in Photolab - XMP?? No,
IPTC
IPTC-Contact
IPTC-Content
IPTC-Image
IPTC-Status
I think one of the underlying problems with trying to handle IPTC metadata is there is IPTC metadata and there is IPTC metadata and that not all IPTC metadata is equal, or even valid.
Doing a bit of research brought up that the Keywords tag is part of IPTC-IIM, which is a largely defunct set of tags, that have been “moved” to their XMP equivalents.
It is my belief that PhotoMechanic allows folks to continue managing the IIM tags and, although this might be useful for reading legacy files, it is “highly” not recommended to use them going forwards.
I also believe that the practice of use pipe separators to denote hierarchy is a" leftover" practice from IPTC not providing a specific hierarchical tag. So, Root|Branch|Leaf would have been placed in the IPTC Keywords tag to denote the hierarchy.
PhotoLab does not provide a means for writing the IPTC-IIM-based Keywords tag but, it seems to be able to interpret the xmp-dc:subject tag if Root|Branch|Leaf is somehow written to the the 'xmp-dc:subject`.
I manually altered an XMP sidecar for a RAW file…
<dc:subject>
<rdf:Bag>
<rdf:li>Root|Branch|Leaf</rdf:li>
</rdf:Bag>
</dc:subject>
… and opened the file in PL, to see it had been “interpreted” as…
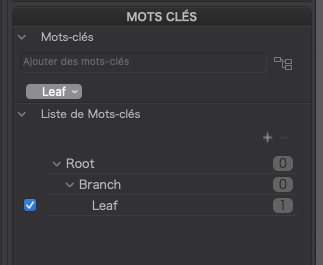
What I entered manually is definitely not a standard format for a “modern” XMP sidecar, which should use lr:hierarchicalSubject for recording the hierarchical relationship between the constituent keywords and xmp-dc:subject to explicitly list all those keywords separately, without any mention of their relationships.
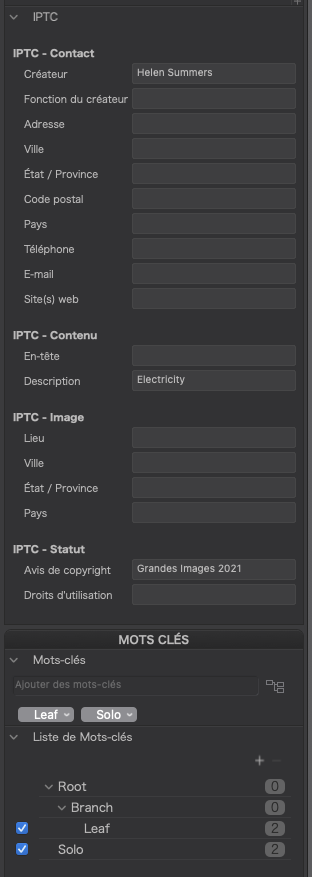
However, if I now edit the keywords that PL shows…
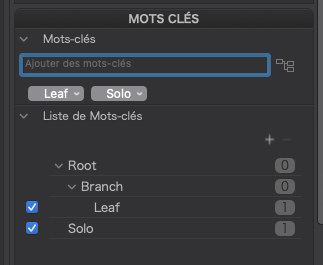
… and rewrite the metadata, I then find that PL has attempted to rewrite the xmp-dc:subject tag to conform to modern XMP standards by separating out the hierarchical context into the lr:hierarchicalSubject tag but, as I mentioned earlier, has instead, written only the Leaf keyword to the xmp-dc:subject instead of, correctly, writing all the members of the hierarchy.
<dc:subject>
<rdf:Bag>
<rdf:li>Leaf</rdf:li>
<rdf:li>Solo</rdf:li>
</rdf:Bag>
</dc:subject>
…
<lr:hierarchicalSubject>
<rdf:Bag>
<rdf:li>Root|Branch|Leaf</rdf:li>
<rdf:li>Solo</rdf:li>
</rdf:Bag>
</lr:hierarchicalSubject>
So, now we have metadata that can no longer be “interpreted” from the pipe-delimited string, written by other IIM-aware software, to denote the hierarchy. And the constituent keywords may not be searchable from software other than PhotoLab, which seems to use its own database rather than the XMP sidecar, due to xmp-dc:subject not being completely defined. in the sidecar.
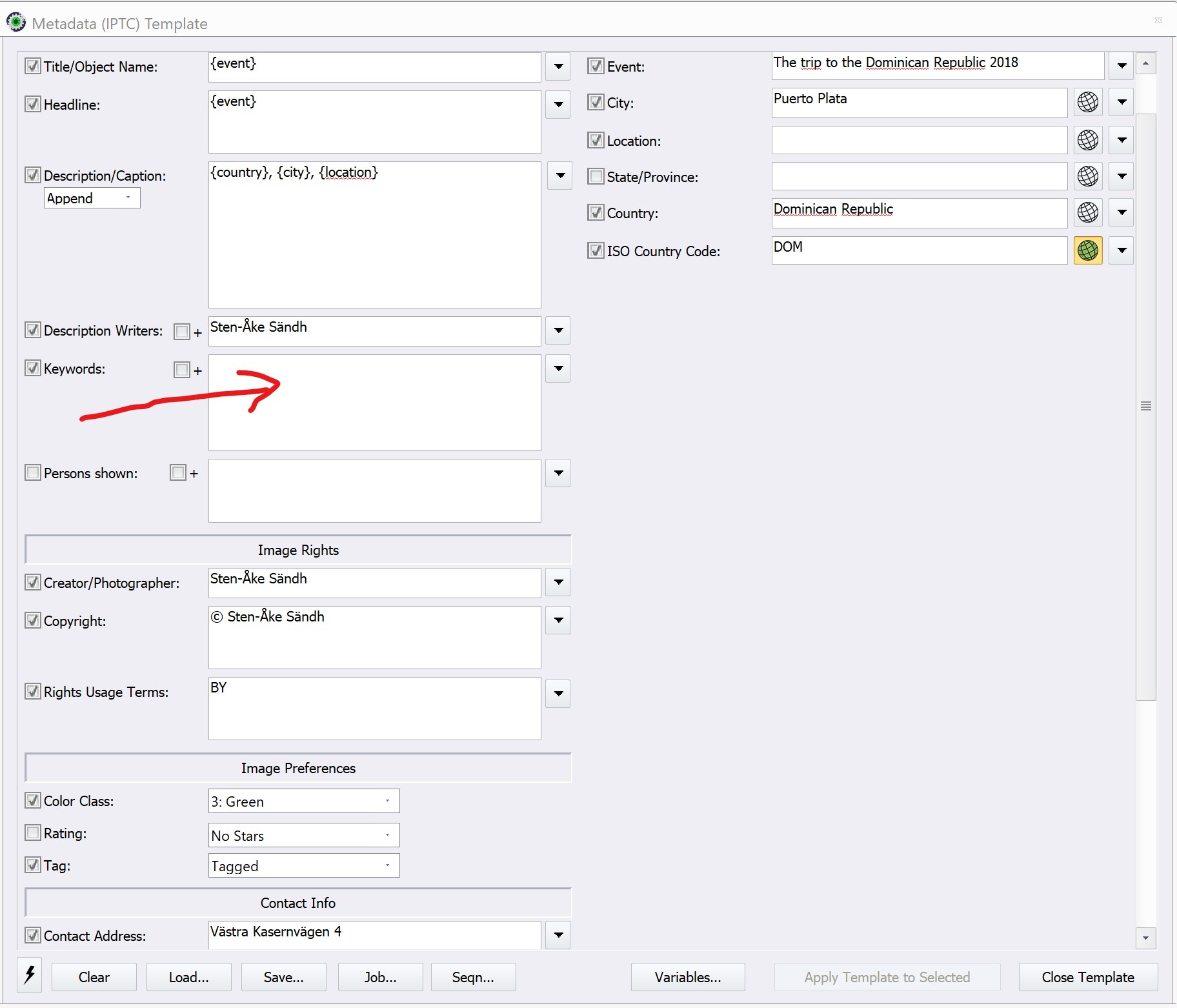
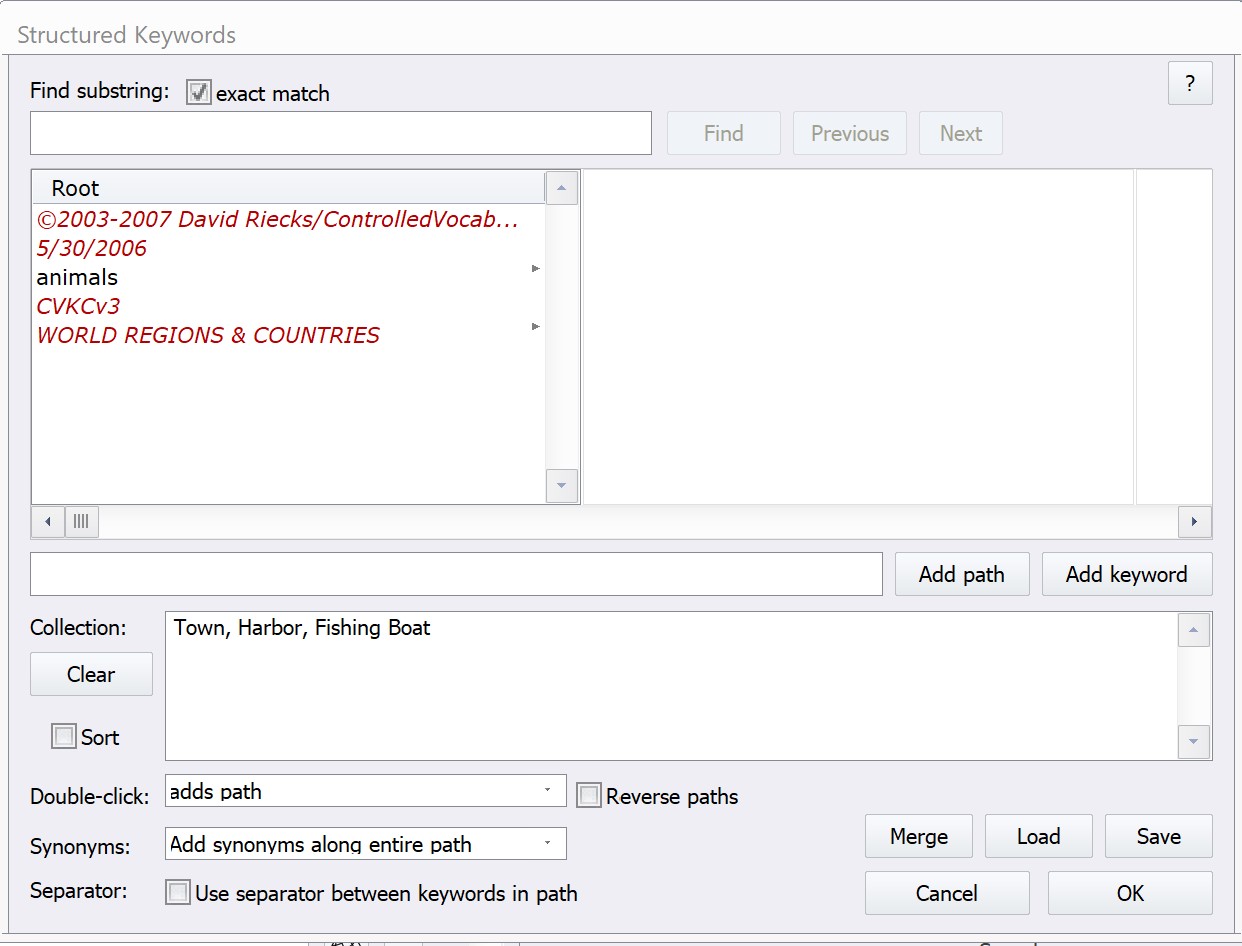
My own software helps avoid a lot of problems by insisting that hierarchies are defined in a separate keyword management window…
… so that they can be provided in a lookup at the time of entry…
In fact, standards like the MWG document encourage the use of dictionaries to help avoiding mis-spellings and incorrect hierarchies. Unfortunately, DxO seem to think that their tiny little palette is enough. Have you ever tried dragging a keyword starting with Z to make it the child of another one beginning with A?
Check the Branch and Root keywords and all three will show, in subject, although pipeless…
If you mean in PL, agreed, but that is not intuitive to everybody and the general reaction tends to be that, if PL can manage without it in the UI, then everybody else’s software can manage as well.
It is very intructive to read all your posts although very difficult to fully understand for me.
Now i will ask: do you think it is a good idea to put keywords to IPTC or no?
If so which software is better to manage that?
Do you recommand PL for tagging your own pictures or another software?
Thank you.
Use what you have and make it the only metadata editor.
And don’t put keywords in IPTC. They belong in XMP
I agree fully with Joanna that there are a lot of discrepancies between different softwares how they handle IPTC and she is also completely right when she writes that: “Doing a bit of research brought up that the Keywords tag is part of IPTC-IIM, which is a largely defunct set of tags, that have been “moved” to their XMP equivalents.” IPTC-IIM is frozen since at least 7or 8 years (2014 i guess).
I had a conversation with Kirk Baker at Camera Bits maybe two years ago asking them about two things:
To start using the same tech like some other Enterprise DAM-systems and monitor the changes in the folder hierarchy they are indexing - today they don´t so in order to se the updates done on the images you have to manually refresh them in PM.
My other request was to open up Photo Mechanic for XMP. XMP stands for Extensible Markup Platform so it is possible to expand with your own “namespaces”. The basic XMP-schema as I remember it from FotoWare DAM that we used at the Digital City Museum of Stockholm had the following default namespaces: Dublin Core, Adobe Photoshop, EXIF and IPTC. So it is already possible to use an XMP-schemas IPTC-namespace and the elements there to build a future “Metadata Template Form” in an XMP-based future version of Photo Mechanic and one day or another I think they will have to rewrite the whole application.
In the Stockholm Museum we added a couple of our own namespaces. One covered our own elements we needed to handle both documents like Office-documents and not the least PDF-files. A real DAM can handle any type of document - not just pictures. Some of the later PDF-files were XMP-compatible like TIFF, JPEG and DNG with a possibility to store the metadata in the fileheaders for XMP and others were not - the system created XMP-sidecars for those. The other namespace was to accommodate the data we had in a legacy “artefact”-SQL-database.
In these systems these XMP-schemas were also used to mapp the integration between these two SQL-databases and the XMP-database in the DAM where it was possible to do all sorts of smart automation when the data was pumped from one system to the other.
What I would love to see is a fully XMP-based Photo Mechanic where photographers that also are entreprenours can use the system not only to keep track of their image assets but also their business documents. Even if they would double the price that would be nothing because building the DAM at the museum costed more than 100 000 U$. So when I saw that I was able to buy Photo Mechanic Plus for less than 200 U$ i could not believe my eyes. Finally I had found a tool that was so efficient that I could feel it was doable to add XMP-data to at least all the images I how have developed. Today they are 24 800 but the total amount is 70 000.
I also started with high expectations and imported a hierarchic vocabulary made in Lightroom in English some one had posted on the net.
… soon I found the interface for structured keywords been very cumbersome to use. I also found myself maintaining that TAB-separated file by exporting it, editing it (appending my own keywords) and importing it again.
When trying to use it together with PL 5 it just didn´t work. In order to get something done I decided just to give upp the structured approach and instead gå for a flat comma delimited keyword approach and that is just so much more effective.
I have read a lot of what Joanna and even BAYT have done the last years and I wonder when they are going to drop it too.
Today I really think my integration between PM PLus and Photolab works absolutely fantastik. As long as I always update in PM Plus and has the “synchronization” turned on it does everything I want without any fuzz at all.
There is today only one major thing I miss and that is a possibility to export and import the keywords used with my current set of images. Actually the import of the used keywords from the images Photolab does beautifully when indexing or opening folders but it is a demand to push the keyword list out to a textfile to edit it and import it back as it is possible to do in both PM Plus and Capture One.
Soner or later you will have to migrate from one system to another. To be sure to be in synk with my keywords in both Photolab and PM Plus I had to use Capture One 23. I had to export a working list from C1 and import back to both PL and PM Plus.
As long as there is no migration path in both directions, I have to say Photolab isn´t more than a toy for hobbyists really. A lot with the PhotoLibrary is really surprisingly good but using for example the keyword lists in Photolab 6 to mark up the images is a real pain. Take a look at how it works in the Keyword-field in PM with flat keywords and learn.
Today you don´t have any choises in many softwares. When it comes to metadata editing tools for images these seems to be stuck with IPTC-IIM in their interfaces of historical reasons. You are supposed to enter keywords in the IPTC-Keywords-element and then the automagics populates the XMP.